召回早前经历的第一代协同过滤技术,让模型可以在数量级巨大的item集中找到用户潜在想要看到的商品。这种方式有很明显的缺点,一个是对于用户而言,只能通过他历史行为去构建候选集,并且会基于算力的局限做截断。所以推荐结果的多样性和新颖性比较局限,导致推荐的有可能都是用户看过的或者买过的商品。之后在Facebook开源了FASSI库之后,基于内积模型的向量检索方案得到了广泛应用,也就是第二代召回技术。这种技术通过将用户和物品用向量表示,然后用内积的大小度量兴趣,借助向量索引实现大规模的全量检索。这里虽然改善了第一代的无法全局检索的缺点,然而这种模式下存在索引构建和模型优化目标不一致的问题,索引优化是基于向量的近似误差,而召回问题的目标是最大化topK召回率。且这类方法也不方便在用户和物品之间做特征组合。
所以阿里开发了一种可以承载各种深度模型来检索用户潜在兴趣的推荐算法解决方案。这个TDM模型是基于树结构,利用树结构对全量商品进行检索,将复杂度由O(N)下降到O(logN)。
树结构
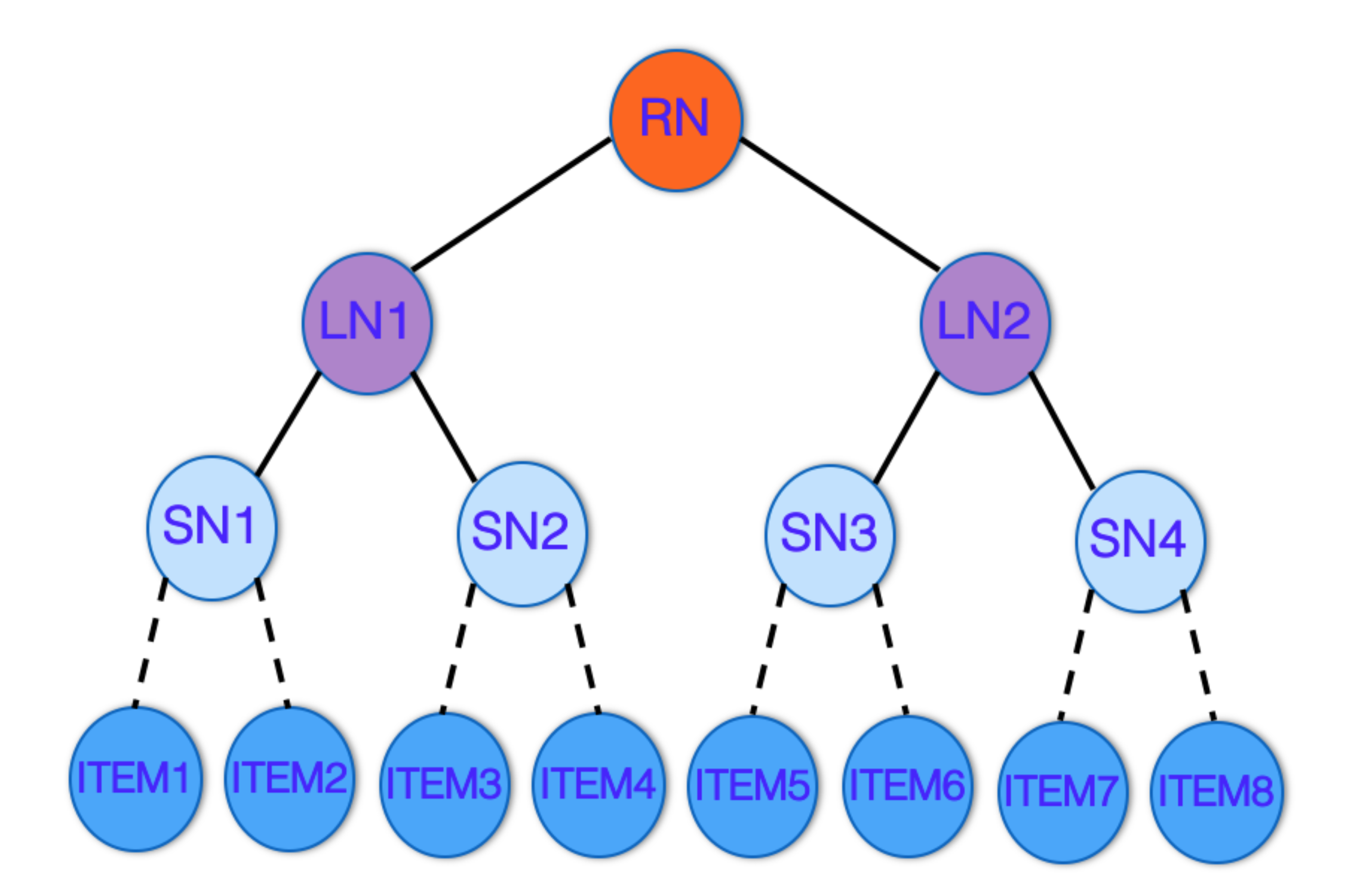
如上图,树中的每一个叶子节点对应一个商品item,非叶子结点表示的是item的集合**(这里的树不限于二叉树)**。这种层次化结构体现了粒度从粗到细的item架构。
整体结构
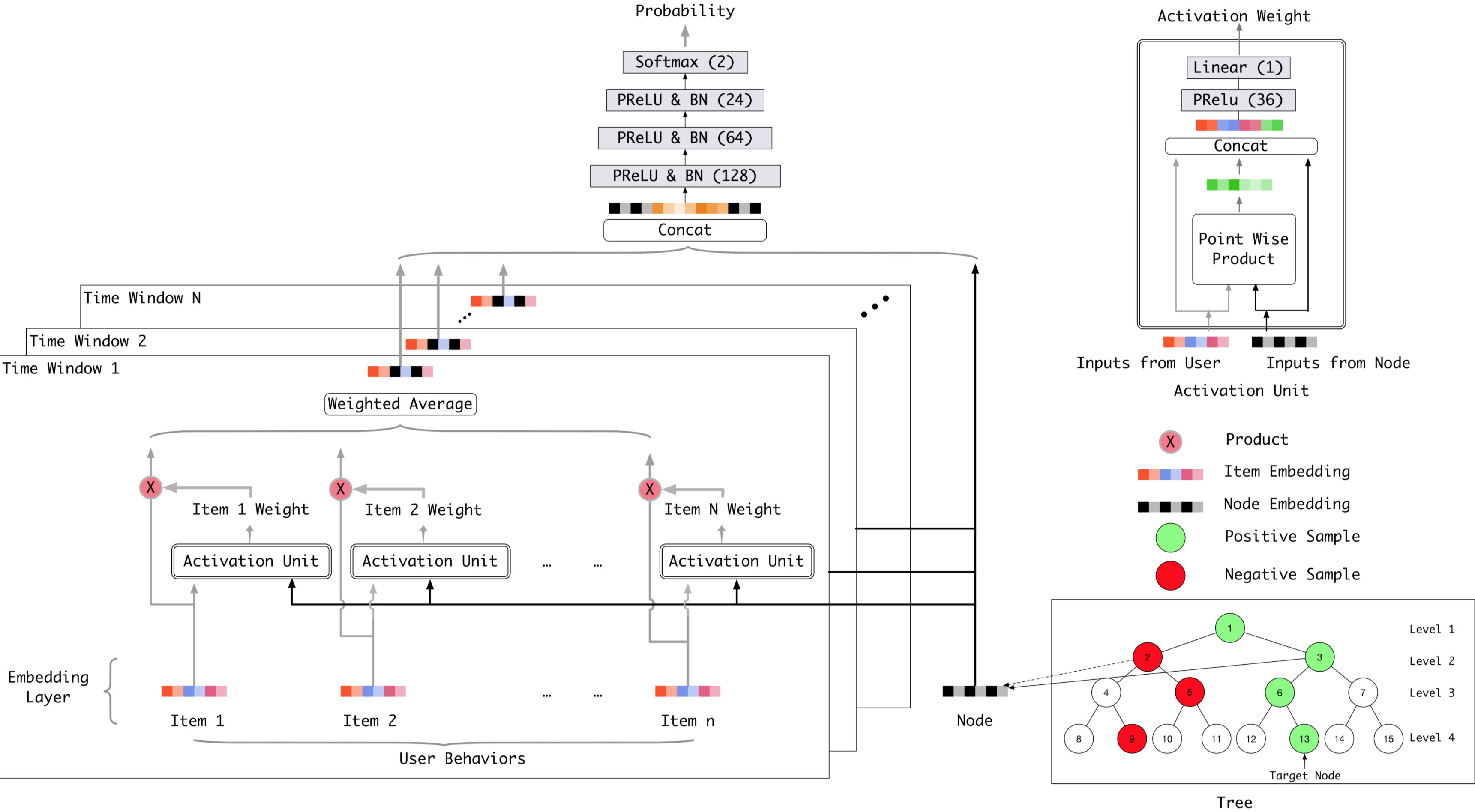
-
基于树的高效检索
算法通常采用beam-search的方法,根据用户对每层节点挑选出topK,将挑选出来的这几个topK节点的子节点作为下一层的候选集,最终会落到叶子节点上。 这么做的理论依据是当前层的最有优topK节点的父亲必然属于上次的父辈节点的最优topK: $$ p^{(j)}(n|u) = {{max \atop{n_{c}\in{{n's children nodes in level j+1}}}}p^{(j+1)}(n_{c}|u) \over {\alpha^{j}}} $$ 其中$p^{(j)}(n|u)$表示用户u对j层节点n感兴趣的概率,$\alpha^{j}$表示归一化因子。
-
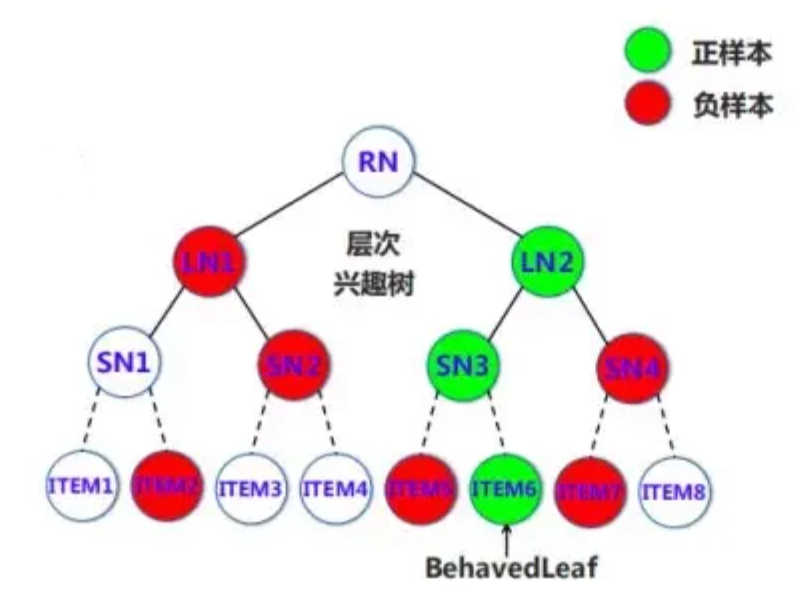
对兴趣进行建模
如上图,用户对叶子层item6感兴趣,可以认为它的兴趣是1,同层别的候选节点的兴趣为0,顺着着绿色线路上去的节点都标记为1,路线上的同层别的候选节点都标记为0。这样的操作就可以根据1和0构建用于每一层的正负样本。
样本构建完成后,可以在模型结构左侧采用任意的深度学习模型来承担用户兴趣判别器的角色,输入就是当前层构造的正负样本,输出则是(用户,节点)对的兴趣度,这个将被用作检索过程中选取topK的评判指标。在整体结构图中,我们可以看到节点特征方面,使用的是node embedding,说明在进入模型前已经向量化了。
-
训练过程
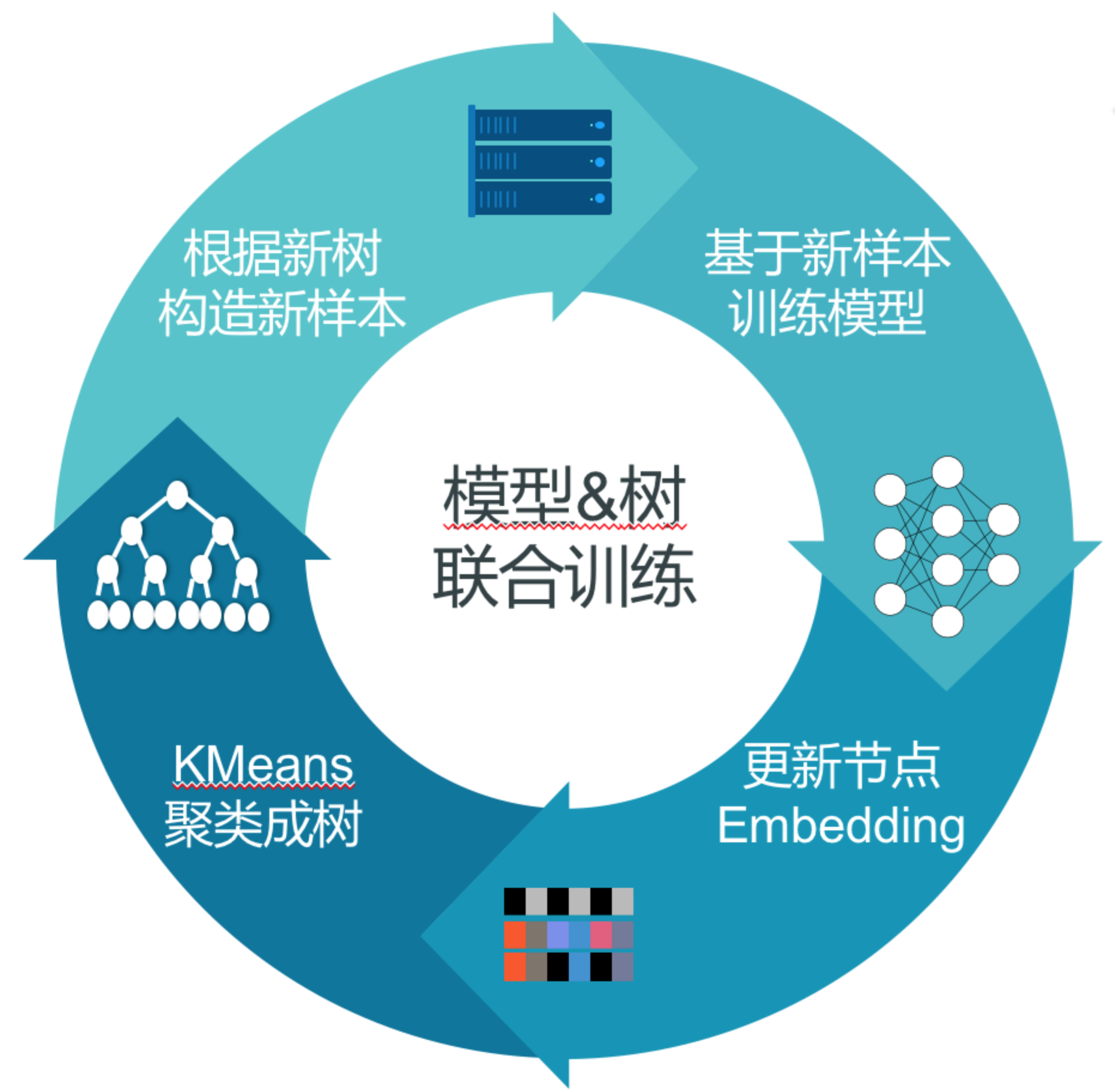
整体联合训练的方式如下:
- 构造随机二叉树
- 基于树模型生成样本
- 训练DNN模型直到收敛
- 基于DNN模型得到样本的Embedding,重新构造聚类二叉树
- 循环上述2~4过程
具体的,在初始化树结构的时候,首先借助商品的类别信息进行排序,将相同类别的商品放到一起,然后递归的将同类别中的商品等量的分到两个子类中,直到集合中只包含一项,利用这种自顶向下的方式来初始化一棵树。基于该树采样生成深度模型训练所需的样本,然后进一步训练模型,训练结束之后可以得到每个树节点对应的Embedding向量,利用节点的Embedding向量,采用K-Means聚类方法来重新构建一颗树,最后基于这颗新生成的树,重新训练深层网络。
参考资料