public class BIO {
public static void main(String[] args) throws Exception {
ServerSocket serverSocket = new ServerSocket(666);
System.out.println("Server started...");
while (true) {
System.out.println("socket accepting...");
Socket socket = serverSocket.accept();
new Thread(new Runnable() {
@Override
public void run() {
try {
byte[] bytes = new byte[1024];
InputStream inputStream = socket.getInputStream();
while (true) {
System.out.println("reading...");
int read = inputStream.read(bytes);
if (read != -1) {
System.out.println(new String(bytes, 0, read));
} else {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}).start();
}
}
}BIO流程图如下:

BIO缺陷:
- BIO中,作为服务端开发,使用ServerSocket 绑定端口号之后会监听该端口,等待accept事件,accept是会阻塞当前线程;
- 当我们收到accept事件的时候,程序就会拿到客户端与当前服务端连接的Socket,针对这个socket我们可以进行读写,但是呢,这个socket读写都是会阻塞当前线程的;
- 一般我们会有使用多线程方式进行c/s交互,但是这样很难做到C10K(比如说:1W个客户端就需要和服务端用1W个线程支持,这样的话CPU肯定就爆炸了,同时线程上下文切换也会把机器负载给拉飞)
NIO流程图如下:

针对BIO的以上不足,NIO提供了解决方案,即NIO提供的selector。在NIO中,提供一个selector用于监听客户端socket的连接事件,当有socket连接进来之后,就需要把检查的客户端socket注册到这个selector中,对于客户端socket来说,其线程就阻塞在了selector的select方法中,此时客户端程序该干啥干啥,不需要像BIO一样维护一个长连接去等待事件。
只有当客户端的selector发现socket就绪了有事件了,才会唤醒线程去处理就绪状态的socket。
当然,NIO也有许多的不足,归纳为以下几点:
- NIO 的类库和 API 繁杂,使用麻烦:需要熟练掌握 Selector、ServerSocketChannel、SocketChannel、ByteBuffer等;
- 需要具备其他的额外技能:要熟悉 Java 多线程编程,因为 NIO 编程涉及到 Reactor 模式,你必须对多线程和网络编程非常熟悉,才能编写出高质量的 NIO 程序;
- 开发工作量和难度都非常大:例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常流的处理等等;
- JDK NIO 的 Bug:例如臭名昭著的 Epoll Bug,它会导致 Selector 空轮询,最终导致 CPU100%。直到 JDK1.7 版本该问题仍旧存在,没有被根本解决;
为什么出现Netty? Netty 对 JDK 自带的 NIO 的 API 进行了封装,解决了上述问题。
- 设计优雅:适用于各种传输类型的统一 API 阻塞和非阻塞 Socket;基于灵活且可扩展的事件模型,可以清晰地分离关注点;高度可定制的线程模型-单线程,一个或多个线程池;
- 使用方便:详细记录的 Javadoc,用户指南和示例;
- 高性能、吞吐量更高:延迟更低;减少资源消耗;最小化不必要的内存复制;
- 安全:完整的 SSL/TLS 和 StartTLS 支持;
- 社区活跃、不断更新:社区活跃,版本迭代周期短,发现的 Bug 可以被及时修复,同时,更多的新功能会被加入;
Netty是什么?
- Netty是一个异步的、基于事件驱动的网络应用框架,可以用于快速开发高性能、高可靠的网络IO程序;
- Netty 主要针对在 TCP 协议下,面向 Client 端的高并发应用,或者 Peer-to-Peer 场景下的大量数据持续传输的应用;
- Netty 本质是一个 NIO 框架,Netty在NIO基础上进行了二次封装,所以学习Netty之前得了解NIO基础知识;
- Netty是作为许多开源框架的底层,例如:Dubbo、RocketMQ、ElasticSearch等
小伙伴肯定会非常好奇,Netty为什么能作为这么多优秀框架的底层实现?Netty为什么这么高性能?
Netty的高性能主要可以总结为如下几点:
- Netty作为异步事件驱动的网络,高性能之处主要来自于其I/O模型和线程处理模型,不同于传统BIO,客户端的连接以及事件处理都阻塞在同一个线程里,Netty则将客户端的线程和处理客户端的线程分离开来;(高效的Reactor线程模型)
- Netty的IO线程NioEventLoop由于聚合了多路复用器Selector,可以同时并发处理成百上千个客户端连接;(IO多路复用模型)
- Netty底层还实现了零拷贝,避免了IO过程中数据在操作系统底层来回”无效的“拷贝和系统态切换;(零拷贝)
- 无锁串行化设计,串行设计:消息的处理尽可能在一个线程内完成,期间不进行线程切换,避免了多线程竞争和同步锁的使用;(单线程)
- Netty 默认提供了对Google Protobuf 的支持,通过扩展Netty 的编解码接口,可以实现其它的高性能序列化框架(高性能的序列化框架)
- Netty中大量使用了volatile,读写锁,CAS和原子类;(高效并发编程)
- Netty的内存分配管理实现非常高效,Netty内存管理分为了池化(Pooled)和非池化(UnPooled),heap(堆内内存)和direct(堆外内存),对于Netty默认使用的是池化内存管理,其内部维护了一个内存池可以循环的创建ByteBuf(Netty底层实现的一个Buffer),提升了内存的使用效率,降低由于高负载导致的频繁GC。同时Netty底层实现了jemalloc算法(jemalloc3实现的满二叉树,读内存进行一个分隔、jemalloc4则优化了jemalloc3的算法,实现了将内存切割成了一个二维数组维护的一个数据结构,提升了内存的使用率)(Netty内存管理非常高效)
基于以上的这么多的优点,是非常推荐阅读Netty底层源码。
TODO
- 不同的线程模式,对程序的性能有很大影响,为了搞清 Netty 线程模式,我们来系统的讲解下各个线程模式,最后看看 Netty 线程模型有什么优越性;
- 目前存在的线程模型有:传统阻塞 I/O 服务模型 和Reactor 模式;
- 根据 Reactor 的数量和处理资源池线程的数量不同,有 3 种典型的实现:
- 单Reactor单线程;
- 单Reactor多线程;
- 主从Reactor多线程;
- Netty 线程模式(Netty 主要基于主从 Reactor 多线程模型做了一定的改进,其中主从 Reactor 多线程模型有多个 Reactor)

模型特点
- 采用阻塞 IO 模式获取输入的数据;
- 每个连接都需要独立的线程完成数据的输入,业务处理,数据返回;
问题分析
- 当并发数很大,就会创建大量的线程,占用很大系统资源;
- 连接创建后,如果当前线程暂时没有数据可读,该线程会阻塞在 Handler对象中的read 操作,导致上面的处理线程资源浪费;
I/O 复用结合线程池,就是 Reactor 模式基本设计思想,如图:

针对传统阻塞 I/O 服务模型的 2 个缺点,解决方案:
基于 I/O 多路复用模型:多个连接共用一个阻塞对象ServiceHandler,应用程序只需要在一个阻塞对象等待,无需阻塞等待所有连接。当某个连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
- 基于线程池复用线程资源:不必再为每个连接创建线程,将连接完成后的业务处理任务分配给线程进行处理,一个线程可以处理多个连接的业务。(解决了当并发数很大时,会创建大量线程,占用很大系统资源)
- 基于 I/O 复用模型:多个客户端进行连接,先把连接请求给ServiceHandler。多个连接共用一个阻塞对象ServiceHandler。假设,当C1连接没有数据要处理时,C1客户端只需要阻塞于ServiceHandler,C1之前的处理线程便可以处理其他有数据的连接,不会造成线程资源的浪费。当C1连接再次有数据时,ServiceHandler根据线程池的空闲状态,将请求分发给空闲的线程来处理C1连接的任务。(解决了线程资源浪费的那个问题)
由上引出单Reactor单线程模型图:

方案说明
- select 是前面 I/O 复用模型介绍的标准网络编程 API,可以实现应用程序通过一个select方法来监听多路连接请求
- Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发
- 如果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接完成后的后续业务处理
- 如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应
- Handler 会完成 Read → 业务处理 → Send 的完整业务流程
优缺点分析
- 优点:模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成
- 缺点:性能问题,只有一个线程,无法完全发挥多核 CPU 的性能。Handler在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈
- 缺点:可靠性问题,线程意外终止,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障
- 使用场景:客户端的数量有限,业务处理非常快速,比如 Redis 在业务处理的时间复杂度 O(1) 的情况
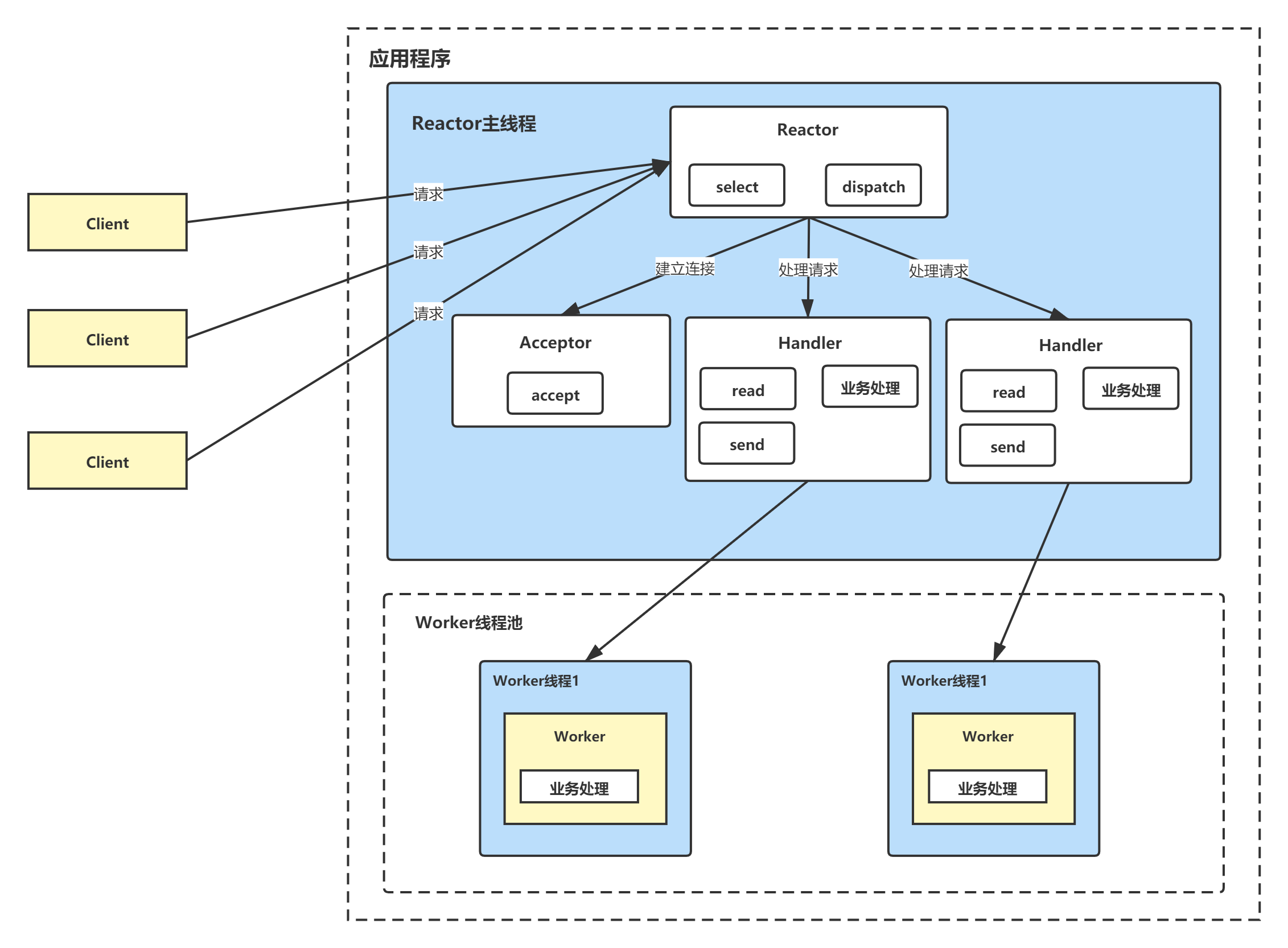
方案说明
- Reactor 对象通过 Select 监控客户端请求事件,收到事件后,通过 Dispatch 进行分发
- 如果是建立连接请求,则由 Acceptor 通过 accept 处理连接请求,然后创建一个 Handler 对象处理完成连接后的各种事件
- 如果不是连接请求,则由 Reactor 分发调用连接对应的 handler 来处理(也就是说连接已经建立,后续客户端再来请求,那基本就是数据请求了,直接调用之前为这个连接创建好的handler来处理)
- handler 只负责响应事件,不做具体的业务处理(这样不会使handler阻塞太久),通过 read 读取数据后,会分发给后面的 worker 线程池的某个线程处理业务。【业务处理是最费时的,所以将业务处理交给线程池去执行】
- worker 线程池会分配独立线程完成真正的业务,并将结果返回给 handler
- handler 收到响应后,通过 send 将结果返回给 client
优缺点分析
- 优点:可以充分的利用多核 cpu 的处理能力
- 缺点:多线程数据共享和访问比较复杂。Reactor 承担所有的事件的监听和响应,它是单线程运行,在高并发场景容易出现性能瓶颈。也就是说Reactor主线程承担了过多的事
针对单 Reactor 多线程模型中,Reactor 在单线程中运行,高并发场景下容易成为性能瓶颈,可以让 Reactor 在多线程中运行

SubReactor是可以有多个的,如果只有一个SubReactor的话那和单 Reactor 多线程就没什么区别了。
方案分析
- Reactor 主线程 MainReactor 对象通过 select 监听连接事件,收到事件后,通过 Acceptor 处理连接事件
- 当 Acceptor 处理连接事件后,MainReactor 将连接分配给 SubReactor
- subreactor 将连接加入到连接队列进行监听,并创建 handler 进行各种事件处理
- 当有新事件发生时,subreactor 就会调用对应的 handler 处理
- handler 通过 read 读取数据,分发给后面的 worker 线程处理
- worker 线程池分配独立的 worker 线程进行业务处理,并返回结果
- handler 收到响应的结果后,再通过 send 将结果返回给 client
- Reactor 主线程可以对应多个 Reactor 子线程,即 MainRecator 可以关联多个 SubReactor
方案优缺点分析
- 优点:父线程与子线程的数据交互简单职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。
- 优点:父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传给子线程,子线程无需返回数据。
- 缺点:编程复杂度较高
这种主从多线程模型在许多优秀的框架中都使用到了,包括Nginx主从Reactor多线程模型,Netty主从多线程模型等。
对于Reactor模式,小结一下:
- 响应快,不必为单个同步时间所阻塞,虽然 Reactor 本身依然是同步的(比如你第一个SubReactor阻塞了,我可以调下一个 SubReactor为客户端服务)
- 可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销
- 扩展性好,可以方便的通过增加 Reactor 实例个数来充分利用 CPU 资源
- 复用性好,Reactor 模型本身与具体事件处理逻辑无关,具有很高的复用性

Netty线程模型流程分析
- Netty 抽象出两组线程池 ,BossGroup 专门负责接收客户端的连接,WorkerGroup 专门负责网络的读写
- BossGroup 和 WorkerGroup 类型都是 NioEventLoopGroup
- NioEventLoopGroup 相当于一个事件循环组,这个组中含有多个事件循环,每一个事件循环是 NioEventLoop
- NioEventLoop 表示一个不断循环的执行处理任务的线程,每个 NioEventLoop 都有一个 Selector,用于监听绑定在其上的 socket 的网络通讯
- NioEventLoopGroup 可以有多个线程,即可以含有多个 NioEventLoop
- 每个 BossGroup下面的NioEventLoop 循环执行的步骤有 3 步
- 轮询 accept 事件
- 处理 accept 事件,与 client 建立连接,生成 NioScocketChannel,并将其注册到某个 workerGroup NIOEventLoop 上的 Selector
- 继续处理任务队列的任务,即 runAllTasks
- 每个 WorkerGroup NIOEventLoop 循环执行的步骤
- 轮询 read,write 事件
- 处理 I/O 事件,即 read,write 事件,在对应 NioScocketChannel 处理
- 处理任务队列的任务,即 runAllTasks
- 每个 Worker NIOEventLoop 处理业务时,会使用 pipeline(管道),pipeline 中包含了 channel(通道),即通过 pipeline 可以获取到对应通道,管道中维护了很多的处理器