Java 8 is not a new topic anymore. There are many good books published on it. Still I meet many Java developers unaware of the power of Java 8. The goal of this tutorial is to cover some of the most important Java 8 features and how they can help developers in their day to day programming.
- Default and Static Methods for Interfaces
- Lambdas
- Streams
- Collectors
- Optionals
- Map improvements
- Building functional programs
- Date Time API
- Completable Futures
- Nashorn
- Tools
We all understand that we should code to interfaces. Interfaces give client a contract which they should use without relying on the implementation details(i.e. classes). Hence, promoting loose coupling. Designing clean interfaces is one of the most important aspect of API design. One of the SOLID principle Interface segregation talks about designing smaller client-specific interfaces instead of designing one general purpose interface. Interface design is the key to clean and effective API's for your libraries and applications.
You can follow the 7 Days with Java 8 series at http://shekhargulati.com/7-days-with-java-8/
If you have designed any API then with time you would have felt the need to add new methods to the API. Once API is published it becomes impossible to add methods to an interface without breaking existing implementations. To make this point clear, let's suppose you are building a client API for a social network and one of the API's that you want to design is to offer user suggestions based on user initials. So, if someone calls your API method with initial sh then you would suggest users like Shekhar, Shankar, Shane. So, you came up with UserSuggester interface as shown below.
public interface UserSuggester {
List<User> suggestions(String initials);
}API turned out to be very useful to the API consumers and some of the consumers decided to have their own implementation of the UserSuggester interface. After talking to your users you came to know that most of them would like to have a way to specify filter criteria as well so that they can filter down user suggestions. It looked a very simple API change so you added one more method to the API -- suggestions(String initials, Predicate<User> predicate).
public interface UserSuggester {
List<User> suggestions(String initials);
List<User> suggestions(String initials, Predicate<User> predicate);
}Adding a method to an interface broke the source compatibility of the API. Adding methods to an interface leads to compilation failures when classes that depend on the interface don't implement the method. This means users who were implementing UserSuggester interface would have to add implementation for suggestions(String initials, Predicate<User> predicate) otherwise their code will not compile. This is a big problem for API designers as it makes difficult to evolve API. Prior to Java 8, it was not possible to have method implementations inside interfaces. This often becomes a problem when it was required to extend an API i.e. adding one or more methods to the interface definition.
Java 8 introduced two ways to declare method with implementations inside an interface. These are:
- static methods: This allows users to declare static methods inside an interface.
Streaminterface has few static helper methods likeof,empty,concat, etc. The static methods inside an interface could be used to replace static helper classes that we normally create to define helper methods associated with a type. For example,Collectionsclass is a helper class that defines various helper methods to work with Collection and associated interfaces. The methods define inCollectionsclass could easily be added toCollectionor its child interface. For example,addAllmethod in theCollectionsclass can be added toCollectioninterface as a static method.
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}- default methods: This allows users to provide default implementations to methods defined in the interface. The class implementing the interface is not required to provide implementation of the method. If implementing class provides the implementation then that implementation would be used else default implementation is used.
Listinterface has few default methods defined in it likereplaceAll,sort, andsplitIterator.
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator();
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}We can solve our API problem by defining a default method as shown below.
default List<User> suggestions(String initials, Predicate<User> predicate) {
Objects.requireNonNull(initials);
Objects.requireNonNull(predicate);
return suggestions(initials).stream().filter(predicate).collect(toList());
}A class can extend a single class but can implement multiple interfaces. Now that it is feasible to have method implementations in interfaces Java has multiple inheritance of behavior. Java already has multiple inheritance at type level but now it also has multiple inheritance at behavioral level. There are three resolution rules that helps decide which method will be picked:
- Methods declared in classes win over method defined in interfaces.
interface A {
default void doSth(){
System.out.println("inside A");
}
}
class App implements A{
@Override
public void doSth() {
System.out.println("inside App");
}
public static void main(String[] args) {
new App().doSth();
}
}This will print inside App as methods declared in class have precedence over methods declared in interfaces.
- Otherwise, the most specific interface is selected
interface A {
default void doSth() {
System.out.println("inside A");
}
}
interface B {}
interface C extends A {
default void doSth() {
System.out.println("inside C");
}
}
class App implements C, B, A {
public static void main(String[] args) {
new App().doSth();
}
}This will print inside C.
- Otherwise, class has to call the desired implementation explicitly
interface A {
default void doSth() {
System.out.println("inside A");
}
}
interface B {
default void doSth() {
System.out.println("inside B");
}
}
class App implements B, A {
@Override
public void doSth() {
B.super.doSth();
}
public static void main(String[] args) {
new App().doSth();
}
}This will print inside B.
From today, I am kicking off 7 Days with Java 8 blog series with first blog on Lambdas. One of the most important features in Java 8 is the introduction of Lambda expressions. They make your code concise and allows you to pass behavior around. For some time now, Java is criticized for being verbose and for lacking functional programming capabilities. With functional programming becoming more popular and relevant, Java is forced to embrace the functional style of programming. Else, Java would become irrelevant.
Java 8 is a big step forward in making the world's most popular language adopt the functional style of programming. To support functional programming style, a language needs to support functions as first class citizen. Prior to Java 8, writing a clean functional style code was not possible without the use of an anonymous inner class boilerplate. With the introduction of Lambda expressions, functions have become first class citizen and they can be passed around just like any other variable.
Lambda expressions allow you to define an anonymous function that is not bound to an identifier. You can use them like any other construct in your programming language like variable declaration. Lambda expressions are required if a programming language needs to support higher order functions. Higher order functions are functions that either accept other functions as arguments or returns a function as a result.
Now, with the introduction of Lambda expressions in Java 8, Java supports higher order functions. Let us look at the canonical example of Lambda expression -- a sort function in Java's Collections class. The sort function has two variants -- one that takes a List and another that takes a List and a Comparator. The second sort function is an example of a Higher order function that accepts a lambda expression as shown below in the code snippet.
List<String> names = Arrays.asList("shekhar", "rahul", "sameer");
Collections.sort(names, (first, second) -> first.length() - second.length());The code shown above sorts the names by their length. The output of the program will be as shown below.
[rahul, sameer, shekhar]
The expression (first, second) -> first.length() - second.length() shown above in the code snippet is a lambda expression of type Comparator<String>.
- The
(first, second)are parameters of thecomparemethod ofComparator. first.length() - second.length()is the function body that compares the length of two names.->is the lambda operator that separates parameters from the body of the lambda.
Before we dig deeper into Java 8 Lambdas support, let's look into their history to understand why they exist.
Lambda expressions have their roots in the Lambda Calculus. Lambda calculus originated from the work of Alonzo Church on formalizing the concept of expressing computation with functions. Lambda calculus is turing complete formal mathematical way to express computations. Turing complete means you can express any mathematical computation via lambdas.
Lambda calculus became the basis of strong theoretical foundation of functional programming languages. Many popular functional programming languages like Haskell, Lisp are based on Lambda calculus. The idea of higher order functions i.e. a function accepting other functions came from Lambda calculus.
The main concept in Lambda calculus is expressions. An expression can be expressed as:
<expression> := <variable> | <function>| <application>
-
variable -- A variable is a placeholder like x, y, z for values like 1, 2, etc or lambda functions.
-
function -- It is an anonymous function definition that takes one variable and produces another lambda expression. For example,
λx.x*xis a function to compute square of a number. -
application -- This is the act of applying a function to an argument. Suppose you want a square of 10, so in lambda calculus you will write a square function
λx.x*xand apply it to 10. This function application would result in(λx.x*x) 10 = 10*10 = 100.You can not only apply simple values like 10 but, you can apply a function to another function to produce another function. For example,(λx.x*x) (λz.z+10)will produce a functionλz.(z+10)*(z+10). Now, you can use this function to produce number plus 10 squares. This is an example of higher order function.
Now, you understand Lambda calculus and its impact on functional programming languages. Let's learn how they are implemented in Java 8.
Before Java 8, the only way to pass behavior was to use anonymous classes. Suppose you want to send an email in another thread after user registration. Before Java 8, you would write code like one shown below.
sendEmail(new Runnable() {
@Override
public void run() {
System.out.println("Sending email...");
}
});The sendEmail method has following method signature.
public static void sendEmail(Runnable runnable)The problem with the above mentioned code is not only that we have to encapsulate our action i.e. run method in an object but, the bigger problem is that it misses the programmer intent i.e. to pass behavior to sendEmail function. If you have used libraries like Guava then, you would have certainly felt the pain of writing anonymous classes. A simple example of filtering all the tasks with lambda in their title is shown below.
Iterable<Task> lambdaTasks = Iterables.filter(tasks, new Predicate<Task>() {
@Override
public boolean apply(Task task) {
return input.getTitle().contains("lambda");
}
});With Java 8 Stream API, you can write the above mentioned code without the use of a third party library like Guava. We will cover streams on Day 2. So, stay tuned!!
In Java 8, we would write the code using a lambda expression as show below. We have mentioned the same example in the code snippet above.
sendEmail(() -> System.out.println("Sending email..."));The code shown above is concise and does not pollute the programmer's intent to pass behavior. () is used to represent no function parameters i.e. Runnable interface run method does not have any parameters. -> is the lambda operator that separates the parameters from the function body which prints Sending email... to the standard output.
Let's look at the Collections.sort example again so that we can understand how lambda expressions work with the parameters. To sort a List of names by their length, we used Collections.sort function as shown below.
Comparator<String> comparator = (first, second) -> first.length() - second.length();The lambda expression that we wrote was corresponding to compare method in the Comparator interface. The signature of compare function is shown below.
int compare(T o1, T o2);T is the type parameter passed to Comparator interface. In this case it will be a String as we are working over a List of String i.e. names.
In the lambda expression, we didn't have to explicitly provide the type -- String. The javac compiler inferred the type information from its context. The Java compiler inferred that both parameters should be String as we are sorting a List of String and compare method use only one T type. The act of inferring type from the context is called Type Inference. Java 8 improves the already existing type inference system in Java and makes it more robust and powerful to support lambda expressions. javac under the hoods look for the information close to your lambda expression and uses that information to find the correct type for the parameters.
In most cases,
javacwill infer the type from the context. In case it can't resolve type because of missing or incomplete context information then the code will not compile. For example, if we removeStringtype information fromComparatorthen code will fail to compile as shown below.
Comparator comparator = (first, second) -> first.length() - second.length(); // compilation error - Cannot resolve method 'length()'You may have noticed that the type of a lambda expression is some interface like Comparator in the above example. You can't use any interface with lambda expression. Only those interfaces which have only one non-object abstract method can be used with lambda expressions. These kinds of interfaces are called Functional interfaces and they are annotated with @FunctionalInterface annotation. Runnable interface is an example of functional interface as shown below. @FunctionalInterface annotation is not mandatory but, it can help tools know that an interface is a functional interface and perform meaningful actions. For example, if you try to compile an interface that annotates itself with @FunctionalInterface annotation and has multiple abstract methods then compilation will fail with an error Multiple non-overriding abstract methods found. Similarly, if you add @FunctionInterface annotation to an interface without any method i.e. a marker interface then you will get error message No target method found.
@FunctionalInterface
public interface Runnable {
public abstract void run();
}Let's answer one of the most important questions that might be coming to your mind. Are Java 8 lambda expressions just the syntactic sugar over anonymous inner classes or how does functional interface gets translated to bytecode?
The short answer is NO. Java 8 does not use anonymous inner classes mainly for two reasons:
- Performance impact: If lambda expressions were implemented using anonymous classes then each lambda expression would result in a class file on disk. When these classes are loaded by JVM at startup, then startup time of JVM will increase as all the classes needs to be first loaded and verified before they can be used.
- Possibility to change in future: If Java 8 designers would have used anonymous classes from the start then it would have limited the scope of future lambda implementation changes.
Java 8 designers decided to use invokedynamic instruction added in Java 7 to defer the translation strategy at runtime. Whenjavac compiles the code, it captures the lambda expression and generates an invokedynamic call site (called lambda factory). The invokedynamic call site when invoked returns an instance of the Functional Interface to which the lambda is being converted. For example, if we look at the byte code of our Collections.sort example, it will look like as shown below.
public static void main(java.lang.String[]);
Code:
0: iconst_3
1: anewarray #2 // class java/lang/String
4: dup
5: iconst_0
6: ldc #3 // String shekhar
8: aastore
9: dup
10: iconst_1
11: ldc #4 // String rahul
13: aastore
14: dup
15: iconst_2
16: ldc #5 // String sameer
18: aastore
19: invokestatic #6 // Method java/util/Arrays.asList:([Ljava/lang/Object;)Ljava/util/List;
22: astore_1
23: invokedynamic #7, 0 // InvokeDynamic #0:compare:()Ljava/util/Comparator;
28: astore_2
29: aload_1
30: aload_2
31: invokestatic #8 // Method java/util/Collections.sort:(Ljava/util/List;Ljava/util/Comparator;)V
34: getstatic #9 // Field java/lang/System.out:Ljava/io/PrintStream;
37: aload_1
38: invokevirtual #10 // Method java/io/PrintStream.println:(Ljava/lang/Object;)V
41: return
}
The interesting part of the byte code shown above is the line 23 23: invokedynamic #7, 0 // InvokeDynamic #0:compare:()Ljava/util/Comparator; where a call to invokedynamic is made.
The second step is to convert the body of the lambda expression into a method that will be invoked through the invokedynamic instruction. This is the step where JVM implementers have the liberty to choose their own strategy.
I have only glossed over this topic. You can read about internals at http://cr.openjdk.java.net/~briangoetz/lambda/lambda-translation.html.
-
In anonymous classes,
thisrefers to the anonymous class itself whereas in lambda expressionthisrefers to the class enclosing the lambda expression. -
You can shadow variables in the enclosing class inside the anonymous class. This gives compile time error when done inside lambda expression.
-
Type of the lambda expression is determined from the context where as type of the anonymous class is specified explicitly as you create the instance of anonymous class.
By default, Java 8 comes with many functional interfaces which you can use in your code. They exist inside java.util.function package. Let's have a look at few of them.
This functional interface is used to define check for some condition i.e. a predicate. Predicate interface has one method called test which takes a value of type T and return boolean. For example, from a list of names if we want to filter out all the names which starts with s then we will use a predicate as shown below.
Predicate<String> namesStartingWithS = name -> name.startsWith("s");This functional interface is used for performing actions which does not produce any output. Predicate interface has one method called accept which takes a value of type T and return nothing i.e. it is void. For example, sending an email with given message.
Consumer<String> messageConsumer = message -> System.out.println(message);This functional interface takes one value and produces a result. For example, if we want to uppercase all the names in our names list, we can write a Function as shown below.
Function<String, String> toUpperCase = name -> name.toUpperCase();We will cover more functional interfaces as we move along in the series.
There would be times when you will be creating lambda expressions that only calls a specific method like Function<String, Integer> strToLength = str -> str.length();. The lambda only calls length() method on the String object. This could be simplified using method references like Function<String, Integer> strToLength = String::length;. They can be seen as shorthand notation for lambda expression that only calls a single method. In the expression String::length, String is the target reference, :: is the delimiter, and length is the function that will be called on the target reference. You can use method references on both the static and instance methods.
Suppose we have to find a maximum number from a list of numbers then we can write a method reference Function<List<Integer>, Integer> maxFn = Collections::max. max is a static method in the Collections class that takes one argument of type List. You can then call this like maxFn.apply(Arrays.asList(1, 10, 3, 5)). The above lambda expression is equivalent to Function<List<Integer>, Integer> maxFn = (numbers) -> Collections.max(numbers); lambda expression.
This is used for method reference to an instance method for example String::toUpperCase calls toUpperCase method on a String reference. You can also use method reference with parameters for example BiFunction<String, String, String> concatFn = String::concat. The concatFn can be called as concatFn.apply("shekhar", "gulati"). The String concat method is called on a String object and passed a parameter like "shekhar".concat("gulati").
Let's look at the code shown below and apply what we have learnt so far.
public class Exercise_Lambdas {
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<String> titles = taskTitles(tasks);
for (String title : titles) {
System.out.println(title);
}
}
public static List<String> taskTitles(List<Task> tasks) {
List<String> readingTitles = new ArrayList<>();
for (Task task : tasks) {
if (task.getType() == TaskType.READING) {
readingTitles.add(task.getTitle());
}
}
return readingTitles;
}
}The code shown above first fetches all the Tasks from a utility method getTasks. We are not interested in getTasks implementation. The getTasks could fetch tasks by accessing a web-service or database or in-memory. Once you have tasks, we filter all the reading tasks and extract the title field from the task. We add extracted title to a list and then finally return all the reading titles.
Let' start with the simplest refactor -- using foreach on a list with method reference.
public class Exercise_Lambdas {
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<String> titles = taskTitles(tasks);
titles.forEach(System.out::println);
}
public static List<String> taskTitles(List<Task> tasks) {
List<String> readingTitles = new ArrayList<>();
for (Task task : tasks) {
if (task.getType() == TaskType.READING) {
readingTitles.add(task.getTitle());
}
}
return readingTitles;
}
}Using Predicate<T> to filter out tasks.
public class Exercise_Lambdas {
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<String> titles = taskTitles(tasks, task -> task.getType() == TaskType.READING);
titles.forEach(System.out::println);
}
public static List<String> taskTitles(List<Task> tasks, Predicate<Task> filterTasks) {
List<String> readingTitles = new ArrayList<>();
for (Task task : tasks) {
if (filterTasks.test(task)) {
readingTitles.add(task.getTitle());
}
}
return readingTitles;
}
}Using Function<T,R> for extracting out title from the Task.
public class Exercise_Lambdas {
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<String> titles = taskTitles(tasks, task -> task.getType() == TaskType.READING, task -> task.getTitle());
titles.forEach(System.out::println);
}
public static <R> List<R> taskTitles(List<Task> tasks, Predicate<Task> filterTasks, Function<Task, R> extractor) {
List<R> readingTitles = new ArrayList<>();
for (Task task : tasks) {
if (filterTasks.test(task)) {
readingTitles.add(extractor.apply(task));
}
}
return readingTitles;
}
}Using method reference for extractor
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<String> titles = filterAndExtract(tasks, task -> task.getType() == TaskType.READING, Task::getTitle);
titles.forEach(System.out::println);
List<LocalDate> createdOnDates = filterAndExtract(tasks, task -> task.getType() == TaskType.READING, Task::getCreatedOn);
createdOnDates.forEach(System.out::println);
List<Task> filteredTasks = filterAndExtract(tasks, task -> task.getType() == TaskType.READING, Function.identity());
filteredTasks.forEach(System.out::println);
}We can also write our own Functional Interface that clearly tells the reader intent of the developer. We can create an interface TaskExtractor that extends Function interface. The input type of interface is fixed to Task and output type depend on the implementing lambda. This way developer will only have to worry about the result type as input type will always remain Task.
public class Exercise_Lambdas {
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<Task> filteredTasks = filterAndExtract(tasks, task -> task.getType() == TaskType.READING, TaskExtractor.identityOp());
filteredTasks.forEach(System.out::println);
}
public static <R> List<R> filterAndExtract(List<Task> tasks, Predicate<Task> filterTasks, TaskExtractor<R> extractor) {
List<R> readingTitles = new ArrayList<>();
for (Task task : tasks) {
if (filterTasks.test(task)) {
readingTitles.add(extractor.apply(task));
}
}
return readingTitles;
}
}
interface TaskExtractor<R> extends Function<Task, R> {
static TaskExtractor<Task> identityOp() {
return t -> t;
}
}On day 1, we learnt how lambdas can help us write clean concise code by allowing us to pass behavior without the need to create a class. Lambdas is a very simple language construct that helps developer express their intent on the fly by using functional interfaces. The real power of lambdas can be experienced when an API is designed keeping lambdas in mind i.e. a fluent API that makes use of Functional interfaces(we discussed them on day 1).
One such API that makes heavy use of lambdas is Stream API introduced in JDK 8. Streams provide a higher level abstraction to express computations on Java collections in a declarative way similar to how SQL helps you declaratively query data in the database. Declarative means developers write what they want to do rather than how it should be done. Almost every Java developer has used Collection API for storing, accessing, and manipulating data. In this blog, we will discuss why need a new API, difference between Collection and Stream, and how to use Stream API in your applications.
-
Collection API is too low level: Collection API does not provide higher level constructs to query the data so developers are forced to write a lot of boilerplate code for the most trivial task.
-
Limited language support to process Collections in parallel
Look at the code shown below and try to predict what code does.
public class Example1_Java7 {
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<Task> readingTasks = new ArrayList<>();
for (Task task : tasks) {
if (task.getType() == TaskType.READING) {
readingTasks.add(task);
}
}
Collections.sort(readingTasks, new Comparator<Task>() {
@Override
public int compare(Task t1, Task t2) {
return t1.getTitle().length() - t2.getTitle().length();
}
});
for (Task readingTask : readingTasks) {
System.out.println(readingTask.getTitle());
}
}
}The code shown above prints all the reading task titles sorted by their title length. All Java developers write this kind of code everyday. To write such a simple program we had to write 15 lines of Java code. The bigger problem with the above mentioned code is not the number of lines a developer has to write but, it misses the developer's intent i.e. filtering reading tasks, sorting by title length, and transforming to List of String.
The above mentioned code can be simplified using Java 8 streams as shown below.
public class Example1_Stream {
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<String> readingTasks = tasks.stream()
.filter(task -> task.getType() == TaskType.READING)
.sorted((t1, t2) -> t1.getTitle().length() - t2.getTitle().length())
.map(Task::getTitle)
.collect(Collectors.toList());
readingTasks.forEach(System.out::println);
}
}The line tasks.stream().filter(task ->task.getType() == TaskType.READING).sorted((t1, t2) -> t1.getTitle().length() - t2.getTitle().length()).map(Task::getTitle).collect(Collectors.toList()) constructs a stream pipeline composing of multiple stream operations as discussed below.
-
stream() - You created a stream pipeline by invoking the
stream()method on the source collection i.e.tasksList<Task>. -
filter(Predicate) - This operation extract elements in the stream matching the condition defined by the predicate. Once you have a stream you can call zero or more intermediate operations on it. The lambda expression
task -> task.getType() == TaskType.READINGdefines a predicate to filter all reading tasks. The type of lambda expression isjava.util.function.Predicate<Task>. -
sorted(Comparator): This operation returns a stream consisting of all the stream elements sorted by the Comparator defined by lambda expression i.e.
(t1, t2) -> t1.getTitle().length() - t2.getTitle().length()in the example shown above. -
map(Function<T,R>): This operation returns a stream after applying the Function<T,R> on each element of this stream.
-
collect(toList()) - This operation collects result of the operations performed on the Stream to a List.
In my opinion Java 8 code is better because of following reasons:
- Java 8 code clearly reflect developer intent
- Developer expressed what they want to do rather than how they want do it
- Stream API provides a unified language for data processing
- No boilerplate code
Stream is a sequence of elements where elements are computed on demand. Streams are lazy by nature and they are only computed when accessed. This allows us to produce infinite streams. In Java before version 8, there was no way to produce infinite elements. With Java 8, you can very easily write a Stream that will produce infinite unique identifiers as shown below.
public static void main(String[] args) {
Stream<String> uuidStream = Stream.generate(() -> UUID.randomUUID().toString());
}
The code shown above will create a Stream that can produce infinite UUID's. If you run this program nothing will happen as Streams are lazy and until they are accessed nothing will be computed. If we update the program to the one shown below we will see UUID printing to the console. The program will never terminate.
public static void main(String[] args) {
Stream<String> uuidStream = Stream.generate(() -> UUID.randomUUID().toString());
uuidStream.forEach(System.out::println);
}Java 8 allows you to create Stream from a Collection by calling the stream method on it. Stream supports data processing operations so that developers can express computations using higher level data processing constructs.
The table shown below explains the difference between a Collection and a Stream.

The difference between Java 8 Stream API code and Collection API code shown above is who controls the iteration, the iterator or the client that uses the iterator. Users of the Stream API just provide the operations they want to apply, and iterator applies those operations to every element in the underlying Collection. When iterating over the underlying collection is handled by the iterator itself, it is called internal iteration. On the other hand, when iteration is handled by the client then it is called external iteration. The use of for-each construct in the Collection API code is an example of external iteration.
Some might argue that in the Collection API code we didn't have to work with the underlying iterator as the for-each construct took care of that but, for-each is nothing more than syntactic sugar over manual iteration using the iterator API. The for-each construct although very simple has few disadvantages -- 1) It is inherently sequential 2) It leads to imperative code 3) It is difficult to parallelize.
When we work with Collection API, every operation that we perform is eagerly evaluated. Look at the example code shown below.
private static List<String> findAllReadingTask(List<Task> tasks) {
List<Task> readingTasks = new ArrayList<>();
for (Task task : tasks) {
if (task.getType() == TaskType.READING) {
readingTasks.add(task);
}
}
Collections.sort(readingTasks, new Comparator<Task>() {
@Override
public int compare(Task o1, Task o2) {
return o1.getCreatedOn().compareTo(o2.getCreatedOn());
}
});
List<String> readingTaskTitles = new ArrayList<>();
for (Task readingTask : readingTasks) {
readingTaskTitles.add(readingTask.getTitle());
}
return readingTaskTitles;
}The code shown above finds all the reading tasks sorted by their creation date. If you look at the code closely you will see that this code does three things -- 1) Filter all reading tasks 2) Sort all filtered tasks by creation date 3) Collect all the titles in a list. These three stages are eagerly evaluated and we had to create temporary variables like readingTasks to store the intermediate values.
In Java 8, we can write the above mentioned code as shown below.
private static List<String> findAllReadingTask(List<Task> tasks) {
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted((t1, t2) -> t1.getCreatedOn().compareTo(t2.getCreatedOn())).
map(task -> task.getTitle()).
collect(Collectors.toList());
}The code shown above does the same work but, the user is not concerned about the iteration and creating temporary variables for storing intermediate results. Java 8 lazily evaluates the stream pipeline when terminal operation(collect(toList())) is called. We will not worry about Stream API methods like map, filter, sorted for now as they will be covered later in the blog. To make sure you understand the lazy evaluation concept, let's look at another example as shown below.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = numbers.stream().map(n -> n / 0).filter(n -> n % 2 == 0);As you can see in the code above, we are dividing by 0 so it will throw ArithmeticException when the code is executed. But, when you run the code no exception is thrown. This is because streams are not evaluated until a terminal operation is called on the stream. If you add terminal operation to the stream pipeline, then stream is executed, and exception is thrown.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = numbers.stream().map(n -> n / 0).filter(n -> n % 2 == 0);
stream.collect(toList());You will get stack trace as shown below.
Exception in thread "main" java.lang.ArithmeticException: / by zero
at org._7dayswithx.java8.day2.EagerEvaluationExample.lambda$main$0(EagerEvaluationExample.java:13)
at org._7dayswithx.java8.day2.EagerEvaluationExample$$Lambda$1/1915318863.apply(Unknown Source)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:512)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:502)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
Stream API provides a lot of operations that developers can use to query data from collections. Stream operations fall into either of the two categories -- intermediate operation or terminal operation. Intermediate operations are functions that produce another stream from the existing stream like filter, map, sorted, etc. Terminal operations are functions that produce a non-stream result from the Stream like collect(toList()) , forEach, count etc. Intermediate operations allows you to build the pipeline which gets executed when you call the terminal operation. Below is the list of functions that are part of the Stream API.
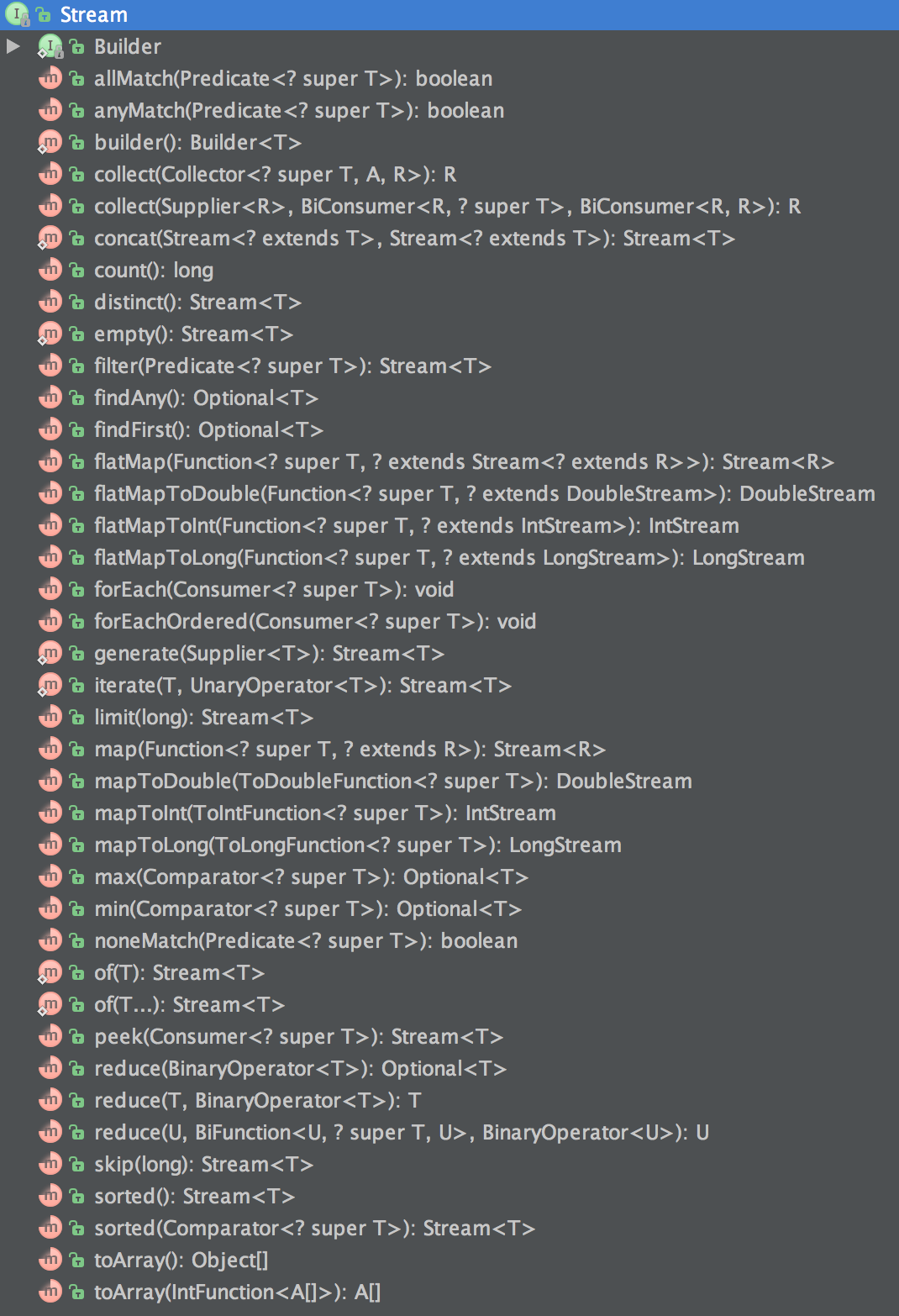
Throughout the series we will use Task management domain to explain the concepts. Our example domain has one class called Task -- a task to be performed by user. The class is shown below.
import java.time.LocalDate;
import java.util.*;
public class Task {
private final String id;
private final String title;
private final TaskType type;
private final LocalDate createdOn;
private boolean done = false;
private Set<String> tags = new HashSet<>();
private LocalDate dueOn;
// removed constructor, getter, and setter for brevity
}The sample dataset is given below. We will use this list throughout our Stream API examples.
Task task1 = new Task("Read Version Control with Git book", TaskType.READING, LocalDate.of(2015, Month.JULY, 1)).addTag("git").addTag("reading").addTag("books");
Task task2 = new Task("Read Java 8 Lambdas book", TaskType.READING, LocalDate.of(2015, Month.JULY, 2)).addTag("java8").addTag("reading").addTag("books");
Task task3 = new Task("Write a mobile application to store my tasks", TaskType.CODING, LocalDate.of(2015, Month.JULY, 3)).addTag("coding").addTag("mobile");
Task task4 = new Task("Write a blog on Java 8 Streams", TaskType.WRITING, LocalDate.of(2015, Month.JULY, 4)).addTag("blogging").addTag("writing").addTag("streams");
Task task5 = new Task("Read Domain Driven Design book", TaskType.READING, LocalDate.of(2015, Month.JULY, 5)).addTag("ddd").addTag("books").addTag("reading");
List<Task> tasks = Arrays.asList(task1, task2, task3, task4, task5);We will not discuss about Java 8 Date Time API today. For now, just think of as the fluent API to work with dates.
The first example that we will discuss is to find all the reading task titles sorted by creation date. The operations that we need to perform to code this example are:
- Filter all the tasks that have TaskType as READING.
- Sort the filtered values tasks by
createdOnfield. - Get the value of title for each task.
- Collect the resulting titles in a List.
The following four operations can be easily translated to the code as shown below.
private static List<String> findAllReadingTitlesSortedByCreationDate(List<Task> tasks) {
List<String> readingTaskTitles = tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted((t1, t2) -> t1.getCreatedOn().compareTo(t2.getCreatedOn())).
map(task -> task.getTitle()).
collect(Collectors.toList());
return readingTaskTitles;
}In the code shown above, we used following methods of the Stream API:
- filter: Allows you to specify a predicate to exclude some elements from the underlying stream. The predicate task -> task.getType() == TaskType.READING selects all the tasks whose TaskType is READING.
- sorted: Allows you to specify a Comparator that will sort the stream. In this case, you sorted based on the creation date. The lambda expression (t1, t2) -> t1.getCreatedOn().compareTo(t2.getCreatedOn()) provides implementation of the
comparemethod of Comparator functional interface. - map: It takes a lambda that implements
Function<? super T, ? extends R>which transforms one stream to another stream. The lambda expression task -> task.getTitle() transforms a task into a title. - collect(toList()) It is a terminal operation that collects the resulting reading titles into a List.
We can improve the above Java 8 code by using comparing method of Comparator interface and method references as shown below.
List<String> readingTaskTitles = tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted(Comparator.comparing(Task::getCreatedOn)).
map(Task::getTitle).
collect(Collectors.toList());From Java 8, interfaces can have method implementations in the form of static and default methods. We will cover them later in this series.
In the code shown above, we used a static helper method comparing available in the Comparator interface which accepts a Function that extracts a Comparable key, and returns a Comparator that compares by that key. The method reference Task::getCreatedOn resolves to Function<Task, LocalDate>.
Using function composition, we can very easily write code that reverses the sorting order by calling reversed() method on Comparator as shown below.
import static java.util.Comparator.comparing;
import static java.util.stream.Collectors.toList;
List<String> readingTaskTitles = tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted(comparing(Task::getCreatedOn).reversed()).
map(Task::getTitle).
collect(toList());Suppose, we have a dataset which contains duplicate tasks. We can very easily remove the duplicates and get only distinct elements by using the distinct method on the stream as shown below.
tasks.stream().distinct().collect(toList());The distinct() method converts one stream into another without duplicates. It uses the Object's equals method for determining the object equality. According to Object's equal method contract, when two objects are equal, they are considered duplicates and will be removed from the resulting stream.
The limit function can be used to limit the result set to a given size. limit is a short circuiting operation which means it does not evaluate all the elements to find the result.
List<String> top5 = tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted(comparing(Task::getCreatedOn)).
map(Task::getTitle).
limit(5).
collect(toList());You can use limit along with skip method to create pagination as shown below.
// page starts from 0. So to view a second page `page` will be 1 and n will be 5.
List<String> readingTaskTitles = tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted(comparing(Task::getCreatedOn).reversed()).
map(Task::getTitle).
skip(page * n).
limit(n).
collect(toList());To get the count of all the reading tasks, we can use count method on the stream. This method is a terminal operation.
private static long countAllReadingTasks(List<Task> tasks) {
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
count();
}To find all the distinct tags we have to perform the following operations:
- Extract tags for each task.
- Collect all the tags into one stream.
- Remove the duplicates.
- Finally collect the result into a list.
The first and second operations can be performed by using the flatMap operation on the tasks stream. The flatMap operation flattens the streams returned by each invocation of tasks.getTags().stream() into one stream. Once we have all the tags in one stream, we just used distinct method on it to get all unique tags.
private static List<String> allDistinctTags(List<Task> tasks) {
return tasks.stream().flatMap(task -> task.getTags().stream()).distinct().collect(toList());
}Stream API has methods that allows the users to check if elements in the dataset match a given property. These methods are allMatch, anyMatch, noneMatch, findFirst, and findAny. To check if all reading titles have a tag with name books we can write code as shown below.
private static boolean isAllReadingTasksWithTagBooks(List<Task> tasks) {
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
allMatch(task -> task.getTags().contains("books"));
}To check whether any reading task has a java8 tag, then we can use anyMatch operation as shown below.
private static boolean isAnyReadingTasksWithTagJava8(List<Task> tasks) {
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
anyMatch(task -> task.getTags().contains("java8"));
}Suppose, you want to create a summary of all the titles then you can use reduce operation, which reduces the stream to a value. The reduce function takes a lambda which joins elements of the stream.
private static String joinAllTaskTitles(List<Task> tasks) {
return tasks.stream().
map(Task::getTitle).
reduce((first, second) -> first + " *** " + second).
get();
}Another example of reduce operation is when you have to find the product of squares of all numbers from given a list of numbers. This is a second variant of reduce which takes two values -- 1) An initial value like 1 in this case 2) A BinaryOperator that combines two elements to produce a new value.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Integer result = numbers.stream().map(number -> number * number).reduce(1, (acc, element) -> acc * element);Apart from the generic stream that works over objects, Java 8 also provides specific streams that work over primitive types like int, long, and double. Let's look at few examples of primitive streams.
To create a range of values, we can use range method that creates a stream with value starting from 0 and ending at 9. It excludes 10.
IntStream.range(0, 10).forEach(System.out::println);The rangeClosed method allows you to create streams that includes the upper bound as well. So, the below mentioned stream will start at 1 and end at 10.
IntStream.rangeClosed(1, 10).forEach(System.out::println);You can also create infinite streams using iterate method on the primitive streams as shown below.
LongStream infiniteStream = LongStream.iterate(1, el -> el + 1);To filter out all even numbers in an infinite stream, we can write code as shown below.
infiniteStream.filter(el -> el % 2 == 0).forEach(System.out::println);We can limit the resulting stream by using the limit operation as shown below.
infiniteStream.filter(el -> el % 2 == 0).limit(100).forEach(System.out::println);You can create streams from arrays by using the static stream method on the Arrays class as shown below.
String[] tags = {"java", "git", "lambdas", "machine-learning"};
Arrays.stream(tags).map(String::toUpperCase).forEach(System.out::println);You can also create a stream from the array by specifying the start and end indexes as shown below. Here, starting index is inclusive and ending index is exclusive.
Arrays.stream(tags, 1, 3).map(String::toUpperCase).forEach(System.out::println);One advantage that you get by using Stream abstraction is that now library can effectively manage parallelism as iteration is internal. So, to process a stream in parallel it is as easy as shown below.
String[] urls = {"https://www.google.co.in/", "https://twitter.com/", "http://www.facebook.com/"};
Arrays.stream(urls).parallel().map(url -> getUrlContent(url)).forEach(System.out::println);On day 2, you learned that Stream API can help you work with collections in a declarative manner. We looked at the collect, which is a terminal operation that collects the result set of a stream pipeline in a List. collect is a reduction operation that reduces a stream to a value. The value could be a Collection, Map, or a value object. You can use collect to achieve following:
-
Reducing stream to a single value: Result of the stream execution can be reduced to a single value. Single value could be a
Collectionor numeric value like int, double, etc or a custom value object. -
Group elements in a stream: Group all the tasks in a stream by TaskType. This will result in a
Map<TaskType, List<Task>>with each entry containing a TaskType and its associated Tasks. You can use any other Collection instead of a List as well. If you don't need all the tasks associated with a TaskType you can also produceMap<TaskType, Task>as well. One example could be grouping tasks by type and obtaining the first created task. -
Partition elements in a stream: You can partition a stream into two groups -- due and completed tasks.
To feel the power of Collector let us look at the example where we have to group tasks by their type. In Java 8, we can achieve grouping by TaskType by writing code shown below. Please refer to day 2 blog where we talked about the example domain we will use in this series
private static Map<TaskType, List<Task>> groupTasksByType(List<Task> tasks) {
return tasks.stream().collect(Collectors.groupingBy(task -> task.getType()));
}The code shown above uses groupingBy Collector defined in the Collectors utility class. It creates a Map with key as the TaskType and value as the list containing all the tasks which have same TaskType. To achieve the same in Java 7 you have to write following code.
public static void main(String[] args) {
List<Task> tasks = getTasks();
Map<TaskType, List<Task>> allTasksByType = new HashMap<>();
for (Task task : tasks) {
List<Task> existingTasksByType = allTasksByType.get(task.getType());
if (existingTasksByType == null) {
List<Task> tasksByType = new ArrayList<>();
tasksByType.add(task);
allTasksByType.put(task.getType(), tasksByType);
} else {
existingTasksByType.add(task);
}
}
for (Map.Entry<TaskType, List<Task>> entry : allTasksByType.entrySet()) {
System.out.println(String.format("%s =>> %s", entry.getKey(), entry.getValue()));
}
}Collectors utility class provides a lot of static utility methods for creating collectors for most common use cases like accumulating elements into a Collection, grouping and partitioning elements, summarizing elements according to various criteria. We will cover most common Collectors in this blog.
As discussed above, collectors can be used to collect stream output to a Collection or produce a single value.
Let's write our first test case -- given a list of Tasks we want to collect all the titles into a List.
import static java.util.stream.Collectors.toList;
public class Example2_ReduceValue {
public List<String> allTitles(List<Task> tasks) {
return tasks.stream().map(Task::getTitle).collect(toList());
}
}The toList collector uses the List's add method to add elements into the resulting List. toList collector uses ArrayList as the List implementation.
If we want to make sure only unique titles are returned and we don't care about order then we can use toSet collector.
import static java.util.stream.Collectors.toSet;
public Set<String> uniqueTitles(List<Task> tasks) {
return tasks.stream().map(Task::getTitle).collect(toSet());
}toSet method uses HashSet as the Set implementation to store the result set.
You can convert a stream to a Map by using the toMap collector. The toMap collector takes two mapper functions to extract the key and values for the Map. In the code shown below, Task::getTitle is Function that takes a task and produces a key with only title. The task -> task is a lambda expression that just returns itself i.e. task in this case.
private static Map<String, Task> taskMap(List<Task> tasks) {
return tasks.stream().collect(toMap(Task::getTitle, task -> task));
}We can improve the code shown above by using the identity default method in the Function interface to make code cleaner and better convey developer intent to use identity function as shown below.
import static java.util.function.Function.identity;
private static Map<String, Task> taskMap(List<Task> tasks) {
return tasks.stream().collect(toMap(Task::getTitle, identity()));
}The code to create a Map from the stream will throw an exception when duplicate keys are present. You will get an error like the one shown below.
Exception in thread "main" java.lang.IllegalStateException: Duplicate key Task{title='Read Version Control with Git book', type=READING}
at java.util.stream.Collectors.lambda$throwingMerger$105(Collectors.java:133)
You can handle duplicates by using another variant of the toMap function which allows us to specify a merge function. The merge function allows a client to specify how they want to resolve collisions between values associated with the same key. In the code shown below, we just used the last value but you can write intelligent algorithm to resolve the collision.
private static Map<String, Task> taskMap_duplicates(List<Task> tasks) {
return tasks.stream().collect(toMap(Task::getTitle, identity(), (t1, t2) -> t2));
}You can use any other Map implementation by using the third variant of toMap method. This requires you to specify Map Supplier that will be used to store the result.
public Map<String, Task> collectToMap(List<Task> tasks) {
return tasks.stream().collect(toMap(Task::getTitle, identity(), (t1, t2) -> t2, LinkedHashMap::new));
}
Similar to the toMap collector there is also toConcurrentMap collector that produces ConcurrentMap instead of a HashMap.
The specific collectors like toList and toSet does not allow you to specify the underlying List or Set implementation. You can use toCollection collector when you want to collect the result to other types of collections as shown below.
private static LinkedHashSet<Task> collectToLinkedHaskSet(List<Task> tasks) {
return tasks.stream().collect(toCollection(LinkedHashSet::new));
}
public Task taskWithLongestTitle(List<Task> tasks) {
return tasks.stream().collect(collectingAndThen(maxBy((t1, t2) -> t1.getTitle().length() - t2.getTitle().length()), Optional::get));
}public int totalTagCount(List<Task> tasks) {
return tasks.stream().collect(summingInt(task -> task.getTags().size()));
}public String titleSummary(List<Task> tasks) {
return tasks.stream().map(Task::getTitle).collect(joining(";"));
}One of the most common use case of Collector is to group elements. Let's look at various examples to understand how we can perform grouping.
Let's look the example shown below where we want to group all the tasks based on their TaskType. You can very easily perform this task by using the groupingBy Collector of the Collectors utility class as shown below. You can make it more succinct by using method references and static imports.
import static java.util.stream.Collectors.groupingBy;
private static Map<TaskType, List<Task>> groupTasksByType(List<Task> tasks) {
return tasks.stream().collect(groupingBy(Task::getType));
}It will produce the output shown below.
{CODING=[Task{title='Write a mobile application to store my tasks', type=CODING, createdOn=2015-07-03}], WRITING=[Task{title='Write a blog on Java 8 Streams', type=WRITING, createdOn=2015-07-04}], READING=[Task{title='Read Version Control with Git book', type=READING, createdOn=2015-07-01}, Task{title='Read Java 8 Lambdas book', type=READING, createdOn=2015-07-02}, Task{title='Read Domain Driven Design book', type=READING, createdOn=2015-07-05}]}
private static Map<String, List<Task>> groupingByTag(List<Task> tasks) {
return tasks.stream().
flatMap(task -> task.getTags().stream().map(tag -> new TaskTag(tag, task))).
collect(groupingBy(TaskTag::getTag, mapping(TaskTag::getTask,toList())));
}
private static class TaskTag {
final String tag;
final Task task;
public TaskTag(String tag, Task task) {
this.tag = tag;
this.task = task;
}
public String getTag() {
return tag;
}
public Task getTask() {
return task;
}
}Combining classifiers and Collectors
private static Map<String, Long> tagsAndCount(List<Task> tasks) {
return tasks.stream().
flatMap(task -> task.getTags().stream().map(tag -> new TaskTag(tag, task))).
collect(groupingBy(TaskTag::getTag, counting()));
}private static Map<TaskType, Map<LocalDate, List<Task>>> groupTasksByTypeAndCreationDate(List<Task> tasks) {
return tasks.stream().collect(groupingBy(Task::getType, groupingBy(Task::getCreatedOn)));
}There are times when you want to partition a dataset into two dataset based on a predicate. For example, we can partition tasks into two groups by defining a partitioning function that partition tasks into two groups -- one with due date before today and one with due date after today.
private static Map<Boolean, List<Task>> partitionOldAndFutureTasks(List<Task> tasks) {
return tasks.stream().collect(partitioningBy(task -> task.getDueOn().isAfter(LocalDate.now())));
}Another group of collectors that are very helpful are collectors that produce statistics. These work on the primitive datatypes like int,double, long and can be used to produce statistics like the one shown below.
IntSummaryStatistics summaryStatistics = tasks.stream().map(Task::getTitle).collect(summarizingInt(String::length));
System.out.println(summaryStatistics.getAverage()); //32.4
System.out.println(summaryStatistics.getCount()); //5
System.out.println(summaryStatistics.getMax()); //44
System.out.println(summaryStatistics.getMin()); //24
System.out.println(summaryStatistics.getSum()); //162There are other variants as well for other primitive types like LongSummaryStatistics and DoubleSummaryStatistics
You can also combine one IntSummaryStatistics with another using the combine operation.
firstSummaryStatistics.combine(secondSummaryStatistics);
System.out.println(firstSummaryStatistics)private static String allTitles(List<Task> tasks) {
return tasks.stream().map(Task::getTitle).collect(joining(", "));
}import com.google.common.collect.HashMultiset;
import com.google.common.collect.Multiset;
import java.util.Collections;
import java.util.EnumSet;
import java.util.Set;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
public class MultisetCollector<T> implements Collector<T, Multiset<T>, Multiset<T>> {
@Override
public Supplier<Multiset<T>> supplier() {
return HashMultiset::create;
}
@Override
public BiConsumer<Multiset<T>, T> accumulator() {
return (set, e) -> set.add(e, 1);
}
@Override
public BinaryOperator<Multiset<T>> combiner() {
return (set1, set2) -> {
set1.addAll(set2);
return set1;
};
}
@Override
public Function<Multiset<T>, Multiset<T>> finisher() {
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH));
}
}import com.google.common.collect.Multiset;
import java.util.Arrays;
import java.util.List;
public class MultisetCollectorExample {
public static void main(String[] args) {
List<String> names = Arrays.asList("shekhar", "rahul", "shekhar");
Multiset<String> set = names.stream().collect(new MultisetCollector<>());
set.forEach(str -> System.out.println(str + ":" + set.count(str)));
}
}Every Java developer whether beginner, novice, or seasoned has in his/her lifetime experienced NullPointerException. This is a true fact that no Java developer can deny. We all have wasted or spent many hours trying to fix bugs caused by NullPointerException. According to NullPointerException JavaDoc, NullPointerException is thrown when an application attempts to use null in a case where an object is required.. This means if we invoke a method or try to access a property on null reference then our code will explode and NullPointerException is thrown.
On a lighter note, if you look at the JavaDoc of NullPointerException you will find that author of this exception is unascribed. If the author is unknown unascribed is used(nobody wants to take ownership of NullPointerException ;))
In 2009 at QCon conference Sir Tony Hoare stated that he invented null reference type while designing ALGOL W programming language. null was designed to signify absence of a value. He called null references as a billion-dollar mistake. You can watch the full video of his presentation on Infoq http://www.infoq.com/presentations/Null-References-The-Billion-Dollar-Mistake-Tony-Hoare.
Most of the programming languages like C, C++, C#, Java, Scala, etc. has nullable type as part of their type system which allows the value to be set to a special value Null instead of other possible data type values.
Let's look at the example Task management domain classes shown below. Our domain model is very simple with only two classes -- Task and User. A task can be assigned to a user.
public class Task {
private final String id;
private final String title;
private final TaskType type;
private User assignedTo;
public Task(String id, String title, TaskType type) {
this.id = id;
this.title = title;
this.type = type;
}
public Task(String title, TaskType type) {
this.id = UUID.randomUUID().toString();
this.title = title;
this.type = type;
}
public String getTitle() {
return title;
}
public TaskType getType() {
return type;
}
public User getAssignedTo() {
return assignedTo;
}
public void setAssignedTo(User assignedTo) {
this.assignedTo = assignedTo;
}
}
public class User {
private final String username;
private String fullname;
public User(String username) {
this.username = username;
}
public String getUsername() {
return username;
}
public String getFullname() {
return fullname;
}
public void setFullname(String fullname) {
this.fullname = fullname;
}
}Given the above domain model, if we have to find the User who is assigned a task with id taskId then we would write code as shown below.
public String taskAssignedTo(String taskId) {
return taskRepository.find(taskId).getAssignedTo().getUsername();
}The biggest problem with the code shown above is that absence of the value is not visible in the API i.e. if the task is not assigned to any user then the code will throw NullPointerException when getAssignedTo is called. The taskRepository.find(taskId) and taskRepository.find(taskId).getAssignedTo() could return null. This forces clients of the API to program defensively and check for null checks as shown below.
public String taskAssignedTo(String taskId) throws TaskNotFoundException {
Task task = taskRepository.find(taskId);
if (task != null) {
User assignedTo = task.getAssignedTo();
if (assignedTo != null)
return assignedTo.getUsername();
return "NotAssigned";
}
throw new TaskNotFoundException(String.format("No task exist with id '%s'", taskId));
}The code shown above misses developer intent and bloats client code with if-null checks. The developer somehow wanted to use optional data type but he was forced to write if-null checks. I am sure you would have written this kind of code in your day to day programming.
A common solution to working with null references is to use Null Object pattern. The idea behind this pattern is very simple instead of returning null you should return a null object that implements your interface or class. So, you can create a NullUser as shown below.
public class NullUser extends User {
public NullUser(String username) {
super("NotAssigned");
}
}So now we could return a NullUser when no user is assigned a task. We can change the getAssignedTo method to return NullUser when no user is assigned a task.
public User getAssignedTo() {
return assignedTo == null ? NullUser.getInstance() : assignedTo;
}Now client code can be simplified to not use null check for user as shown below. In this example, it does not make sense to use Null Object pattern for Task because non-existence of task in the repository is an exception situation. Also, by adding TaskNotFoundException in the throws clause we have made it explicit for the client that this code can throw exception.
public String taskAssignedTo(String taskId) throws TaskNotFoundException {
Task task = taskRepository.find(taskId);
if (task != null) {
return task.getAssignedTo().getUsername();
}
throw new TaskNotFoundException(String.format("No task exist with id '%s'", taskId));
}Java 8 introduced a new data type java.util.Optional which encapsulates an empty value. It makes intent of the API clear. If a function returns a value of type Optional then it tells the clients that value might not be present. Use of Optional data type makes it explicit to the API client when it should expect an optional value. When you use Optional type then you as a developer makes it visible via the type system that value may not be present and client can cleanly work with it. The purpose of using Optional type is to help API designers design APIs that makes it visible to their clients by looking at the method signature whether they should expect optional value or not.
Let's update our domain model to reflect optional values.
import java.util.Optional;
import java.util.UUID;
public class Task {
private final String id;
private final String title;
private final TaskType type;
private Optional<User> assignedTo;
public Task(String title, TaskType type) {
this.id = UUID.randomUUID().toString();
this.title = title;
this.type = type;
this.assignedTo = Optional.empty();
}
public Optional<User> getAssignedTo() {
return assignedTo;
}
public void setAssignedTo(User assignedTo) {
this.assignedTo = Optional.of(assignedTo);
}
}
public class User {
private final String username;
private Optional<String> fullname;
public User(String username) {
this.username = username;
this.fullname = Optional.empty();
}
public String getUsername() {
return username;
}
public Optional<String> getFullname() {
return fullname;
}
public void setFullname(String fullname) {
this.fullname = Optional.of(fullname);
}
}Use of Optional data type in the data model makes it explicit that Task refers to an Optional and User has an Optional username. Now whoever tries to work with assignedTo User would know that it might not be present and they can handle it in a declarative way. We will talk about Optional.empty and Optional.of methods in the next section.
In the domain model shown above, we used couple of creational methods of the Optional class but I didn't talked about them. Let's now discuss three creational methods which are part of the Optional API.
-
Optional.empty: This is used to create an Optional when value is not present like we did above
this.assignedTo = Optional.empty();in the constructor. -
Optional.of(T value): This is used to create an Optional from a non-null value. It throws
NullPointerExceptionwhen value is null. We used it in the code shown abovethis.fullname = Optional.of(fullname);. -
Optional.ofNullable(T value): This static factory method works for both null and non-null values. For null values it will create an empty Optional and for non-null value it will create Optional using the value.
Below is a simple example of how you can write API using Optional.
public class TaskRepository {
private static final Map<String, Task> TASK_STORE = new ConcurrentHashMap<>();
public Optional<Task> find(String taskId) {
return Optional.ofNullable(TASK_STORE.get(taskId));
}
public void add(Task task) {
TASK_STORE.put(task.getId(), task);
}
}Optional can be thought as a Stream with one element. It has methods similar to Stream API like map, filter, flatmap that we can use to work with values contained in the Optional.
To read the value of title for a Task we would write code as shown below. The map function was used to transform from Optional to Optional. The orElseThrow method is used to throw a custom business exception when no Task is found.
public String taskTitle(String taskId) {
return taskRepository.
find(taskId).
map(Task::getTitle).
orElseThrow(() -> new TaskNotFoundException(String.format("No task exist for id '%s'",taskId)));
}There are three variants of orElse* method:
-
orElse(T t): This is used to return a value when exists or returns the value passed as parameter like
Optional.ofNullable(null).orElse("NoValue"). This will returnNoValueas no value exist. -
orElseGet: This will return the value if present otherwise invokes the
Suppliersgetmethod to produce a new value. For example,Optional.ofNullable(null).orElseGet(() -> UUID.randomUUID().toString()could be used to lazily produce value only when no value is present. -
orElseThrow: This allow clients to throw their own custom exception when value is not present.
The find method shown above returns an Optional<Task> that the client can use to get the value. Suppose we want to get the task's title from the Optional, we can do that by using the map function as shown below.
To get the username of the user who is assigned a task we can use the flatMap method as shown below.
public String taskAssignedTo(String taskId) {
return taskRepository.
find(taskId).
flatMap(task -> task.getAssignedTo().map(user -> user.getUsername())).
orElse("NotAssigned");
}The third Stream API like operation supported by Optional is filter, which allows you to filter an Optional based on property as shown in example below.
public boolean isTaskDueToday(Optional<Task> task) {
return task.flatMap(Task::getDueOn).filter(d -> d.isEqual(LocalDate.now())).isPresent();
}TODO
TODO
So far in this series we have focussed on functional aspects of Java 8 and looked at how to design better API's using Optional and default and static methods in Interfaces. In this blog, we will learn about another new API that will change the way we work with dates -- Date Time API. Almost all Java developers will agree that date and time support prior to Java 8 is far from ideal and most of the time we had to use third party libraries like Joda-Time in our applications. The new Date Time API is heavily influenced by Joda-Time API and if you have used it then you will feel home.
Before we learn about new Date Time API let's understand why existing Date API sucks. Look at the code shown below and try to answer what it will print.
import java.util.Date;
public class DateSucks {
public static void main(String[] args) {
Date date = new Date(12, 12, 12);
System.out.println(date);
}
}Can you answer what above code prints? Most Java developers will expect the program to print 0012-12-12 but the above code prints Sun Jan 12 00:00:00 IST 1913. My first reaction when I learnt that program prints Sun Jan 12 00:00:00 IST 1913 was WTF???
The code shown above has following issues:
-
What each 12 means? Is it month, year, date or date, month, year or any other combination.
-
Date API month index starts at 0. So, December is actually 11.
-
Date API rolls over i.e. 12 will become January.
-
Year starts with 1900. And because month also roll over so year becomes
1900 + 12 + 1 == 1913. Go figure!! -
Who asked for time? I just asked for date but program prints time as well.
-
Why is there time zone? Who asked for it? The time zone is JVM's default time zone, IST, Indian Standard Time in this example.
Date API is close to 20 years old introduced with JDK 1.0. One of the original authors of Date API is none other than James Gosling himself -- Father of Java Programming Language.
There are many other design issues with Date API like mutability, separate class hierarchy for SQL, etc. In JDK1.1 effort was made to provide a better API i.e. Calendar but it was also plagued with similar issues of mutability and index starting at 0.
Java 8 Date Time API was developed as part of JSR-310 and reside insides java.time package. The API applies domain-driven design principles with domain classes like LocalDate, LocalTime applicable to solve problems related to their specific domains of date and time. This makes API intent clear and easy to understand. The other design principle applied is the immutability. All the core classes in the java.time are immutable hence avoiding thread-safety issues.
The three classes that you will encounter most in the new API are LocalDate, LocalTime, and LocalDateTime. Their description is like their name suggests:
-
LocalDate: It represents a date with no time or timezone.
-
LocalTime: It represents time with no date or timezone
-
LocalDateTime: It is the combination of LocalDate and LocalTime i.e. date with time without time zone.
We will use JUnit to drive our examples. We will first write a JUnit case that will explain what we are trying to do and then we will write code to make the test pass. Examples will be based on great Indian president -- A.P.J Abdul Kalam.
import org.junit.Test;
import java.time.LocalDate;
import static org.hamcrest.CoreMatchers.equalTo;
import static org.junit.Assert.assertThat;
public class DateTimeExamplesTest {
private AbdulKalam kalam = new AbdulKalam();
@Test
public void kalamWasBornOn15October1931() throws Exception {
LocalDate dateOfBirth = kalam.dateOfBirth();
assertThat(dateOfBirth.toString(), equalTo("1931-10-15"));
}
}LocalDate has a static factory method of that takes year, month, and date and gives you a LocalDate. To make this test pass, we will write dateOfBirth method in AbdulKalam class using of method as shown below.
import java.time.LocalDate;
import java.time.Month;
public class AbdulKalam {
public LocalDate dateOfBirth() {
return LocalDate.of(1931, Month.OCTOBER, 15);
}
}There is an overloaded of method that takes month as integer instead of Month enum. I recommend using Month enum as it is more readable and clear. There are two other static factory methods to create LocalDate instances -- ofYearDay and ofEpochDay.
The ofYearDay creates LocalDate instance from the year and day of year for example March 31st 2015 is the 90th day in 2015 so we can create LocalDate using LocalDate.ofYearDay(2015, 90).
LocalDate january_21st = LocalDate.ofYearDay(2015, 21);
System.out.println(january_21st); // 2015-01-21
LocalDate march_31st = LocalDate.ofYearDay(2015, 90);
System.out.println(march_31st); // 2015-03-31The ofEpochDay creates LocalDate instance using the epoch day count. The starting value of is 1970-01-01. So, LocalDate.ofEpochDay(1) will give 1970-01-02.
LocalDate instance provide many accessor methods to access different fields like year, month, dayOfWeek, etc.
@Test
public void kalamWasBornOn15October1931() throws Exception {
LocalDate dateOfBirth = kalam.dateOfBirth();
assertThat(dateOfBirth.getMonth(), is(equalTo(Month.OCTOBER)));
assertThat(dateOfBirth.getYear(), is(equalTo(1931)));
assertThat(dateOfBirth.getDayOfMonth(), is(equalTo(15)));
assertThat(dateOfBirth.getDayOfYear(), is(equalTo(288)));
}You can create current date from the system clock using now static factory method.
LocalDate.now()@Test
public void kalamWasBornAt0115() throws Exception {
LocalTime timeOfBirth = kalam.timeOfBirth();
assertThat(timeOfBirth.toString(), is(equalTo("01:15")));
}LocalTime class is used to work with time. Just like LocalDate, it also provides static factory methods for creating its instances. We will use the of static factory method giving it hour and minute and it will return LocalTime as shown below.
public LocalTime timeOfBirth() {
return LocalTime.of(1, 15);
}There are other overloaded variants of of method that can take second and nanosecond.
LocalTime is represented to nanosecond precision.
You can print the current time of the system clock using now method as shown below.
LocalTime.now()You can also create instances of LocalTime from seconds of day or nanosecond of day using ofSecondOfDay and ofNanoOfDay static factory methods.
Similar to LocalDate LocalTime also provide accessor for its field as shown below.
@Test
public void kalamWasBornAt0115() throws Exception {
LocalTime timeOfBirth = kalam.timeOfBirth();
assertThat(timeOfBirth.getHour(), is(equalTo(1)));
assertThat(timeOfBirth.getMinute(), is(equalTo(15)));
assertThat(timeOfBirth.getSecond(), is(equalTo(0)));
}When you want to represent both date and time together then you can use LocalDateTime. LocalDateTime also provides many static factory methods to create its instances. We can use of factory method that takes a LocalDate and LocalTime and gives LocalDateTime instance as shown below.
public LocalDateTime dateOfBirthAndTime() {
return LocalDateTime.of(dateOfBirth(), timeOfBirth());
}There are many overloaded variants of of method which as arguments take year, month, day, hour, min, secondOfDay, nanosecondOfDay.
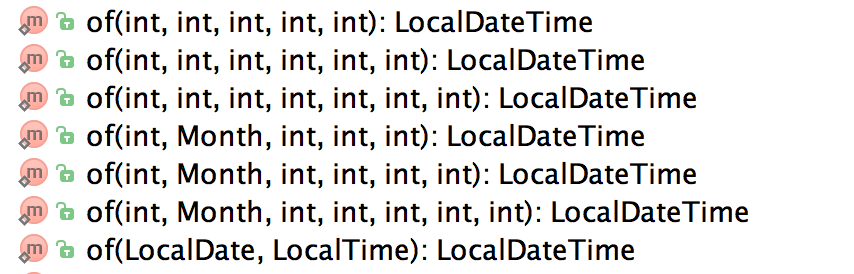
To create current date and time using system clock you can use now factory method.
LocalDateTime.now()Now that we know how to create instances of LocalDate, LocalTime, and LocalDateTime let's learn how we can manipulate them.
LocalDate, LocalTime, and LocalDateTime are immutable so each time you perform a manipulation operation you get a new instance.
@Test
public void kalam50thBirthDayWasOnThursday() throws Exception {
DayOfWeek dayOfWeek = kalam.dayOfBirthAtAge(50);
assertThat(dayOfWeek, is(equalTo(DayOfWeek.THURSDAY)));
}We can use dateOfBirth method that we wrote earlier with plusYears on LocalDate instance to achieve this as shown below.
public DayOfWeek dayOfBirthAtAge(final int age) {
return dateOfBirth().plusYears(age).getDayOfWeek();
}There are similar plus* variants for adding days, months, weeks to the value.
Similar to plus methods there are minus methods that allow you minus year, days, months from a LocalDate instance.
LocalDate today = LocalDate.now();
LocalDate yesterday = today.minusDays(1);Just like LocalDate LocalTime and LocalDateTime also provide similar
plus*andminus*methods.
For this use-case, we will create an infinite stream of LocalDate starting from the Kalam's date of birth using the Stream.iterate method. Stream.iterate method takes a starting value and a function that allows you to work on the initial seed value and return another value. We just incremented the year by 1 and return next year birthdate. Then we transformed LocalDate to DayOfWeek to get the desired output value. Finally, we limited our result set to the provided limit and collected Stream result into a List.
public List<DayOfWeek> allBirthDateDayOfWeeks(int limit) {
return Stream.iterate(dateOfBirth(), db -> db.plusYears(1))
.map(LocalDate::getDayOfWeek)
.limit(limit)
.collect(toList());
}Duration and Period classes represents quantity or amount of time.
Duration represents quantity or amount of time in seconds, nano-seconds, or days like 10 seconds.
Period represents amount or quantity of time in years, months, and days.
@Test
public void kalamLived30601Days() throws Exception {
long daysLived = kalam.numberOfDaysLived();
assertThat(daysLived, is(equalTo(30601L)));
}To calculate number of days kalam lived we can use Duration class. Duration has a factory method that takes two LocalTime, or LocalDateTime or Instant and gives a duration. The duration can then be converted to days, hours, seconds, etc.
public Duration kalamLifeDuration() {
LocalDateTime deathDateAndTime = LocalDateTime.of(LocalDate.of(2015, Month.JULY, 27), LocalTime.of(19, 0));
return Duration.between(dateOfBirthAndTime(), deathDateAndTime);
}
public long numberOfDaysLived() {
return kalamLifeDuration().toDays();
}@Test
public void kalamLifePeriod() throws Exception {
Period kalamLifePeriod = kalam.kalamLifePeriod();
assertThat(kalamLifePeriod.getYears(), is(equalTo(83)));
assertThat(kalamLifePeriod.getMonths(), is(equalTo(9)));
assertThat(kalamLifePeriod.getDays(), is(equalTo(12)));
}We can use Period class to calculate number of years, months, and days kalam lived as shown below. Period's between method works with LocalDate only.
public Period kalamLifePeriod() {
LocalDate deathDate = LocalDate.of(2015, Month.JULY, 27);
return Period.between(dateOfBirth(), deathDate);
}In our day-to-day applications a lot of times we have to parse a text format to a date or time or we have to print a date or time in a specific format. Printing and parsing are very common use cases when working with date or time. Java 8 provides a class DateTimeFormatter which is the main class for formatting and printing. All the classes and interfaces relevant to them resides inside the java.time.format package.
In India, dd-MM-YYYY is the predominant date format that is used in all the government documents like passport application form. You can read more about Date and time notation in India on the wikipedia.
@Test
public void kalamDateOfBirthFormattedInIndianDateFormat() throws Exception {
final String indianDateFormat = "dd-MM-YYYY";
String dateOfBirth = kalam.formatDateOfBirth(indianDateFormat);
assertThat(dateOfBirth, is(equalTo("15-10-1931")));
}The formatDateofBirth method uses DateTimeFormatter ofPattern method to create a new formatter using the specified pattern. All the main main date-time classes provide two methods - one for formatting, format(DateTimeFormatter formatter), and one for parsing, parse(CharSequence text, DateTimeFormatter formatter).
public String formatDateOfBirth(final String pattern) {
DateTimeFormatter formatter = DateTimeFormatter.ofPattern(pattern);
return dateOfBirth().format(formatter);
}For the common use cases, DateTimeFormatter class provides formatters as static constants. There are predefined constants for BASIC_ISO_DATE i.e 20111203 or ISO_DATE i.e. 2011-12-03, etc that developers can easily use in their code. In the code shown below, you can see how to use these predefined formats.
@Test
public void kalamDateOfBirthInDifferentDateFormats() throws Exception {
LocalDate kalamDateOfBirth = LocalDate.of(1931, Month.OCTOBER, 15);
assertThat(kalamDateOfBirth.format(DateTimeFormatter.BASIC_ISO_DATE), is(equalTo("19311015")));
assertThat(kalamDateOfBirth.format(DateTimeFormatter.ISO_LOCAL_DATE), is(equalTo("1931-10-15")));
assertThat(kalamDateOfBirth.format(DateTimeFormatter.ISO_ORDINAL_DATE), is(equalTo("1931-288")));
}Let's suppose we have to parse 15 Oct 1931 01:15 AM to a LocalDateTime instance as shown in code below.
@Test
public void shouldParseKalamDateOfBirthAndTimeToLocalDateTime() throws Exception {
final String input = "15 Oct 1931 01:15 AM";
LocalDateTime dateOfBirthAndTime = kalam.parseDateOfBirthAndTime(input);
assertThat(dateOfBirthAndTime.toString(), is(equalTo("1931-10-15T01:15")));
}We will again use DateTimeFormatter ofPattern method to create a new DateTimeFormatter and then use the parse method of LocalDateTime to create a new instance of LocalDateTime as shown below.
public LocalDateTime parseDateOfBirthAndTime(String input) {
return LocalDateTime.parse(input, DateTimeFormatter.ofPattern("dd MMM yyyy hh:mm a"));
}In Manipulating dates section, we learnt how we can use plus* and minus* methods to manipulate dates. Those methods are suitable for simple manipulation operations like adding or subtracting days, months, or years. Sometimes, we need to perform advance date time manipulation such as adjusting date to first day of next month or adjusting date to next working day or adjusting date to next public holiday then we can use TemporalAdjusters to meet our needs. Java 8 comes bundled with many predefined temporal adjusters for common scenarios. These temporal adjusters are available as static factory methods inside the TemporalAdjusters class.
LocalDate date = LocalDate.of(2015, Month.OCTOBER, 25);
System.out.println(date);// This will print 2015-10-25
LocalDate firstDayOfMonth = date.with(TemporalAdjusters.firstDayOfMonth());
System.out.println(firstDayOfMonth); // This will print 2015-10-01
LocalDate firstDayOfNextMonth = date.with(TemporalAdjusters.firstDayOfNextMonth());
System.out.println(firstDayOfNextMonth);// This will print 2015-11-01
LocalDate lastFridayOfMonth = date.with(TemporalAdjusters.lastInMonth(DayOfWeek.FRIDAY));
System.out.println(lastFridayOfMonth); // This will print 2015-10-30- firstDayOfMonth creates a new date set to first day of the current month.
- firstDayOfNextMonth creates a new date set to first day of next month.
- lastInMonth creates a new date in the same month with the last matching day-of-week. For example, last Friday in October.
I have not covered all the temporal-adjusters please refer to the documentation for the same.

You can write your own adjuster by implementing TemporalAdjuster functional interface. Let's suppose we have to write a TemporalAdjuster that adjusts today's date to next working date then we can use the TemporalAdjusters ofDateAdjuster method to adjust the current date to next working date as show below.
LocalDate today = LocalDate.now();
TemporalAdjuster nextWorkingDayAdjuster = TemporalAdjusters.ofDateAdjuster(localDate -> {
DayOfWeek dayOfWeek = localDate.getDayOfWeek();
if (dayOfWeek == DayOfWeek.FRIDAY) {
return localDate.plusDays(3);
} else if (dayOfWeek == DayOfWeek.SATURDAY) {
return localDate.plusDays(2);
}
return localDate.plusDays(1);
});
System.out.println(today.with(nextWorkingDayAdjuster));TODO
TODO
TODO
You can follow me on twitter at https://twitter.com/shekhargulati or email me at shekhargulati84@gmail.com. Also, you can read my blogs at http://shekhargulati.com/