Small query benchmark
This benchmark shows runtimes of Diamond v2.0.11 and BLAST v2.10.0 of searching the E. coli and A. thaliana proteomes against the NCBI NR database (April 2021, 370 million sequences). The benchmark was run on a AMD Ryzen Threadripper 3960X 24-Core system with 256 GB of RAM.
Note that Diamond is optimized for large query datasets, and using a small query file like the genes of a single organism does not achieve optimal efficiency and speed. Sets of smaller query files should be combined into a larger file and searched together if possible.
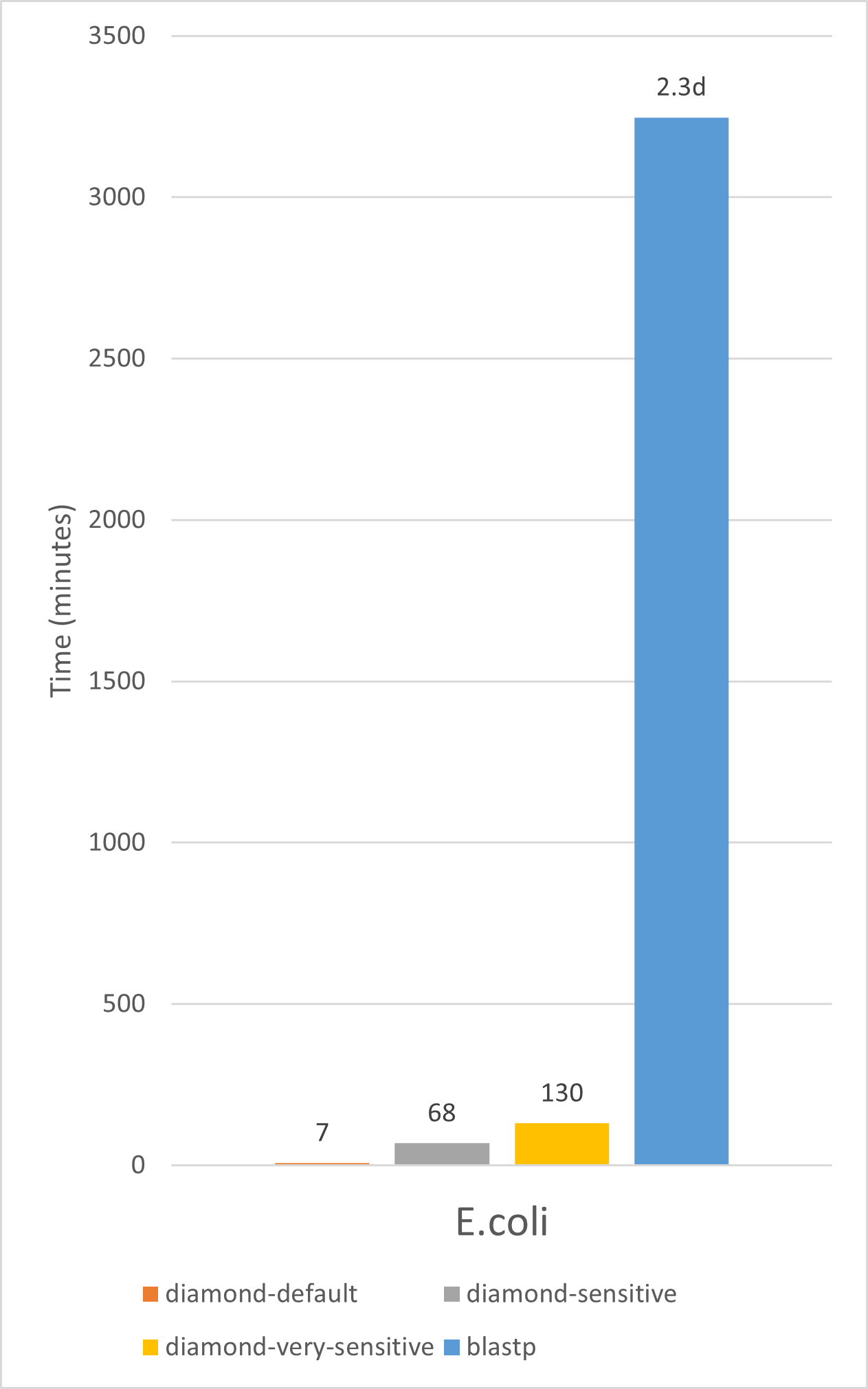
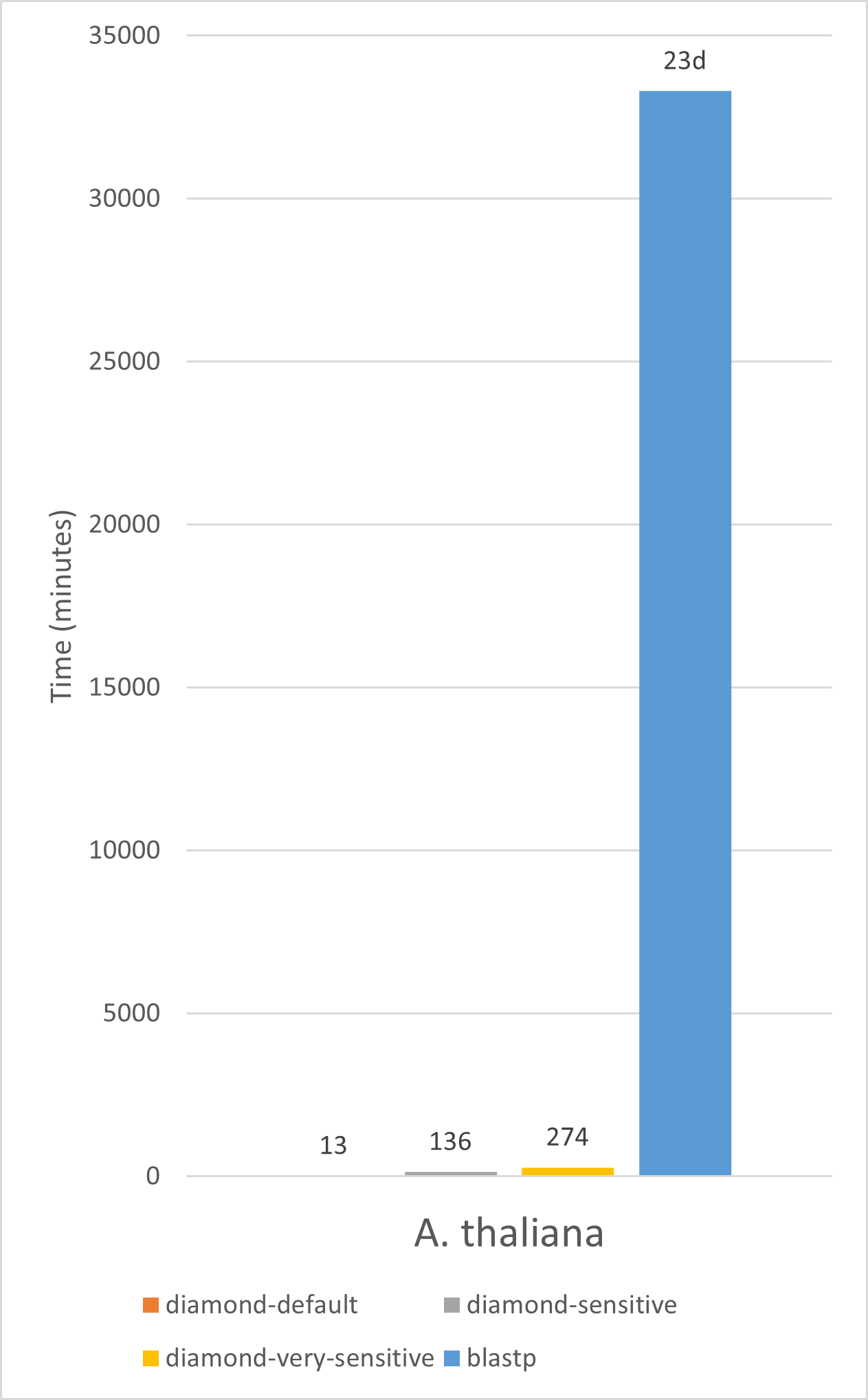
Runtimes for BLAST are estimates based on a sample.
The benchmark was run using Diamond with a database in BLAST format, which can be expected to be more efficient in particular for small query files, since it takes advantage of memory mapped files to cache the database in memory and to load sequences more quickly. Note that several "warmup" runs may be necessary to make the system fully cache a database in memory.
The parameters for the runs were: diamond blastp -c1 -g300
The global ranking -g option is a new heuristic to limit the number of targets for which extensions will be computed for each query, and is useful when only a small number of best hits per query are required. Depending on the desired reporting accuracy, this number should be increased, or the option may be omitted to maintain the more conservative default behaviour.