[QNN] [RFC] QNN Dialect -- Prequantize Models #3591
Comments
|
also cc @ajtulloch @ZihengJiang @vinx13 @eqy @jroesch , @anijain2305 can you please list the API proposals and the reference APIs(in tflite etcs?) Then we can try to get everyone's thoughts on these specific API designs |
|
Let's start with just Requantize to keep it focussed. I would suggest to add +1 if one likes the API, to show that one agrees. QNN proposalTF Requantize
|
|
@FrozenGene @tqchen @u99127 Can you please approve the above API, so that we can discuss/move to next discussion. I have so many things to discuss :) |
|
@anijain2305 Let me look at it afternoon of today or evening. |
|
@anijain2305 to increase the throughput, can you also list other APIs, one per post and we use lazy consensus, wait for a week to see people's feedback then summarize. |
|
There are a couple of things in this gemmlowp quantization example, which you should perhaps consider how it could be supported in your requantize api.
|
|
@jnorwood Thanks for the comment. Both good points. I will keep those abilities, though, outside of the scope of requantize op. |
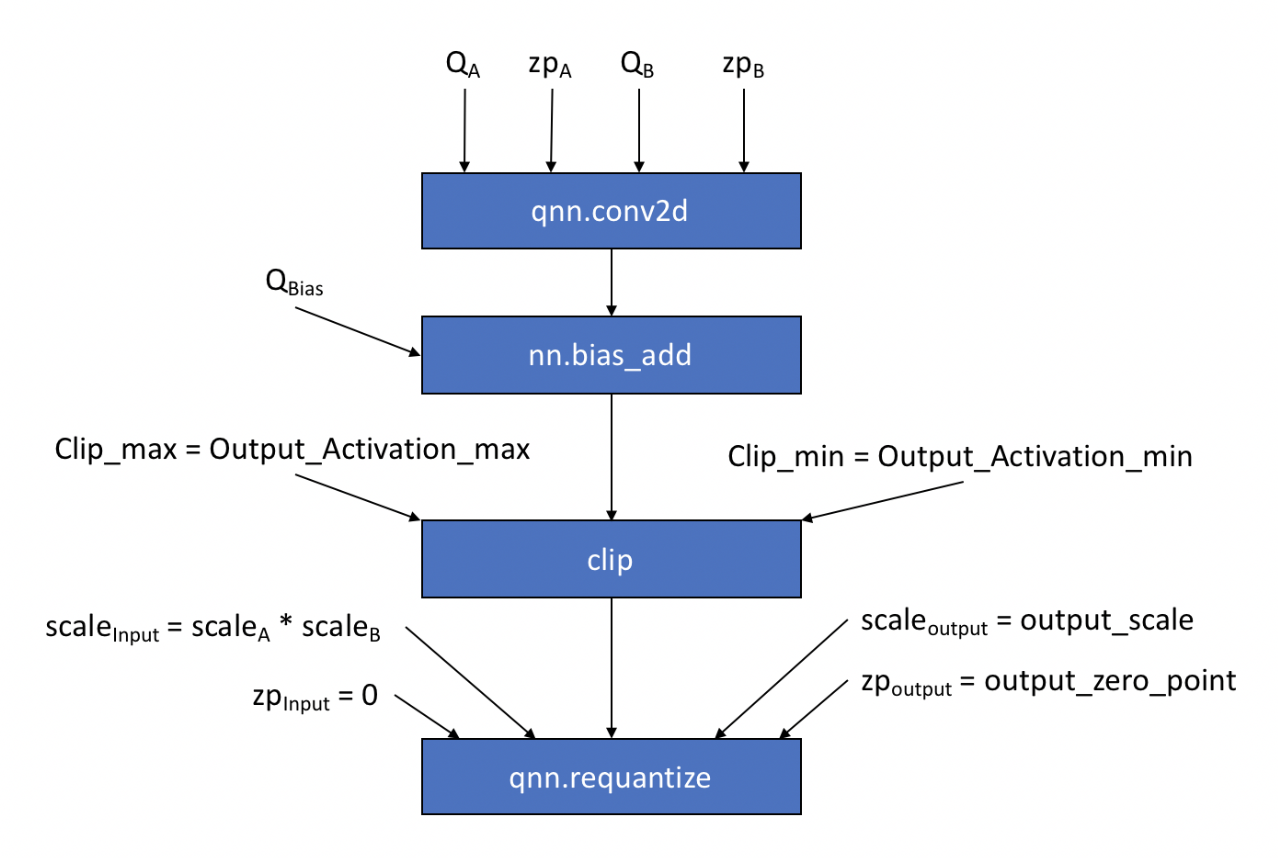
QNN Conv2D operatorTensorflowMxNetTFLiteQNNPACKQNN ProposalKey points
An example of conversion from TFLite to Relay graph will look like this.
|
|
@anijain2305 Could we also list the api of TFLite and QNNPACK? I think both should be considered. Because we will parse TFLite model and QNNPACK is an good quantization accelerated library |
|
The reference integer implementation of tflite conv2d has optional bias parameters which are pointers to 32 bit signed values, where a null pointer can be used to skip the operation. Is it the intention to always separate out the bias add operation in tvm apis? one other comment ... I've seen an implementation of quantized conv2d where the 32 bit signed bias values were preloaded to the accumulator, rather than clearing accumulator prior to the mac loop. I don't recall a discussion of it. I'm wondering if this a common enhancement to reduce overflow/underflow possibility of the signed 32 bit accumulations when a bias is expected? |
|
@FrozenGene Updated the Conv2D API. Also, added a diagram explaining how to go from TFLite to Relay operators. |
|
@jnorwood Yes, bias is kept outside as a separate operator. But, this can be fused with the qnn.conv2d. Regarding the accumulation point, if we perform fusion and add the bias in |
When preloading a negative bias, a signed 32 bit accumulator positive accumulate range is extended (before overflow), for example. Maybe the result from a post bias_add is the same for most implementations, but signed int overflow behavior is undefined in the C standards... so the order of bias_add operations might matter. I saw the bias preload used in some paper. I'll check my notes and see if I can find it. |
|
@anijain2305 Could we list the ConvParams of TFLite? I think it is more clean what TFLite's convolution computation need. For the diagram, I think maybe we could avoid the intermediate |
|
@FrozenGene Thanks for the suggestion to add ConvParams. Just updated the original post. @FrozenGene I dont think We had similar discussion here - #2351 (comment) |
|
I was looking into PR #3531 and #3512 , and noticed that the PRs are going to support 32 bits quantization. I'd like to move to this RFC thread to loop more people with my consideration. Before going far, let me clarify that, First, which is trivial, if we can use 32 bit, why not 32 bit floating point rather than integer. Yes, there is devices supporting only integer, but, the industry shows that 8 bit is enough for accuracy and they are even moving to 4 bit. So, maybe we don't need to be so generic I guess. The less is more :) Second, I wonder that it's impossible to support 32 bit due to arithmetic limitations.
That's the general talking. Strong assumptions may be introduced to handle the issues raised above, but I can hardly see the benefits. Maybe 8 bit quantization is enough so far :) |
|
Thanks @jackwish If in future, we see |
|
@ajtulloch @antinucleon @ZihengJiang @jroesch, would be great if you can also review this week and sign off the APIs |
|
on the discussion of the intermediate formats supported ... The intel avx512 vnni/dlboost operations are simd operations that support 8 bit quantized inference. Their intrinsic descriptions show that the int8 multiplies go to intermediate 16 bit results before they are accumulated (in the fma) to int32 registers. Would it be worth considering how tvm can detect sequences that can be substituted with these dlboost/vnni simd intrinsic operations? If tvm supported operations with 16 bit accumulators, then you could conceivably specify sequences of operations that would exactly match the intrinsic descriptions. Perhaps that would make the intrinsic's pattern easier to detect. From the publicity, I think these dlboost/vnni avx512 simd operations are considered important for the new xeon ai inference support. I'm providing the expanded intrinsic description for one of the ops as an example
|
|
@jackwish, i want to get my understanding correct, when you say
are you talking about the inputs or outputs of quantize/dequantize ops being int32? Because, the current implementation for
Or are you suggesting we should support higher number of bits (>16) for these ops? |
@shoubhik I was saying to limit to int8. I know your PR only restricts to int8, while PR #3531 seems trying to enable int8/16/32. I move to here because I saw the two PRs share same code but seems are not consistent in quantization approach. Thanks for helping to clarify that. |
I am very glad that it helped :) |
Thanks for the explaination. |
|
close as QNN has become part of the repo |
We are proposing a new dialect named
QNN, that introduces a quantized version of existing relay operators. The goal is to support the models that have been pre-quantized in the framework.Some important notes about QNN dialect are
python/relay/qnnand CPP files are insrc/relay/qnn.We can use this thread to discuss various open questions. Some of these questions can be
The idea of QNN dialect was a result of discussion at Issue #2351. Thanks @tqchen @FrozenGene @jackwish @jnorwood @shoubhik for the discussions.
First few PRs for the QNN dialect
The text was updated successfully, but these errors were encountered: