Easily use EasyAnimate inside ComfyUI!
English | 简体中文

The EasyAnimate repository needs to be placed at ComfyUI/custom_nodes/EasyAnimate/.
cd ComfyUI/custom_nodes/
# Git clone the easyanimate itself
git clone https://github.com/aigc-apps/EasyAnimate.git
# Git clone the video outout node
git clone https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite.git
git clone https://github.com/kijai/ComfyUI-KJNodes.git
cd EasyAnimate/
pip install -r comfyui/requirements.txt
EasyAnimateV5.1:
12B:
| Name | Type | Storage Space | Hugging Face | Model Scope | Description |
|---|---|---|---|---|---|
| EasyAnimateV5.1-12b-zh-InP | EasyAnimateV5.1 | 39 GB | 🤗Link | 😄Link | Official image-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
| EasyAnimateV5.1-12b-zh-Control | EasyAnimateV5.1 | 39 GB | 🤗Link | 😄Link | Official video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, and trajectory control. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
| EasyAnimateV5.1-12b-zh-Control-Camera | EasyAnimateV5.1 | 39 GB | 🤗Link | 😄Link | Official video camera control weights, supporting direction generation control by inputting camera motion trajectories. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
| EasyAnimateV5.1-12b-zh | EasyAnimateV5.1 | 39 GB | 🤗Link | 😄Link | Official text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
(Obsolete) EasyAnimateV5:
| Name | Type | Storage Space | Hugging Face | Model Scope | Description |
|---|---|---|---|---|---|
| EasyAnimateV5-12b-zh-InP | EasyAnimateV5 | 34 GB | 🤗Link | 😄Link | Official image-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports bilingual prediction in Chinese and English. |
| EasyAnimateV5-12b-zh-Control | EasyAnimateV5 | 34 GB | 🤗Link | 😄Link | Official video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc. Supports video prediction at multiple resolutions (512, 768, 1024) and is trained with 49 frames at 8 frames per second. Bilingual prediction in Chinese and English is supported. |
| EasyAnimateV5-12b-zh | EasyAnimateV5 | 34 GB | 🤗Link | 😄Link | Official text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports bilingual prediction in Chinese and English. |
(Obsolete) EasyAnimateV4:
| Name | Type | Storage Space | Hugging Face | Model Scope | Description |
|---|---|---|---|---|---|
| EasyAnimateV4-XL-2-InP | EasyAnimateV4 | Before extraction: 8.9 GB / After extraction: 14.0 GB | 🤗Link | 😄Link |
(Obsolete) EasyAnimateV3:
| Name | Type | Storage Space | Hugging Face | Model Scope | Description |
|---|---|---|---|---|---|
| EasyAnimateV3-XL-2-InP-512x512 | EasyAnimateV3 | 18.2GB | 🤗Link | 😄Link | EasyAnimateV3 official weights for 512x512 text and image to video resolution. Training with 144 frames and fps 24 |
| EasyAnimateV3-XL-2-InP-768x768 | EasyAnimateV3 | 18.2GB | 🤗Link | 😄Link | EasyAnimateV3 official weights for 768x768 text and image to video resolution. Training with 144 frames and fps 24 |
| EasyAnimateV3-XL-2-InP-960x960 | EasyAnimateV3 | 18.2GB | 🤗Link | 😄Link | EasyAnimateV3 official weights for 960x960 text and image to video resolution. Training with 144 frames and fps 24 |
- LoadEasyAnimateModel
- Loads the EasyAnimate model
- EasyAnimate_TextBox
- Write the prompt for EasyAnimate model
- EasyAnimateI2VSampler
- EasyAnimate Sampler for Image to Video
- EasyAnimateT2VSampler
- EasyAnimate Sampler for Text to Video
- EasyAnimateV2VSampler
- EasyAnimate Sampler for Video to Video
Our user interface is shown as follows, this is the json:
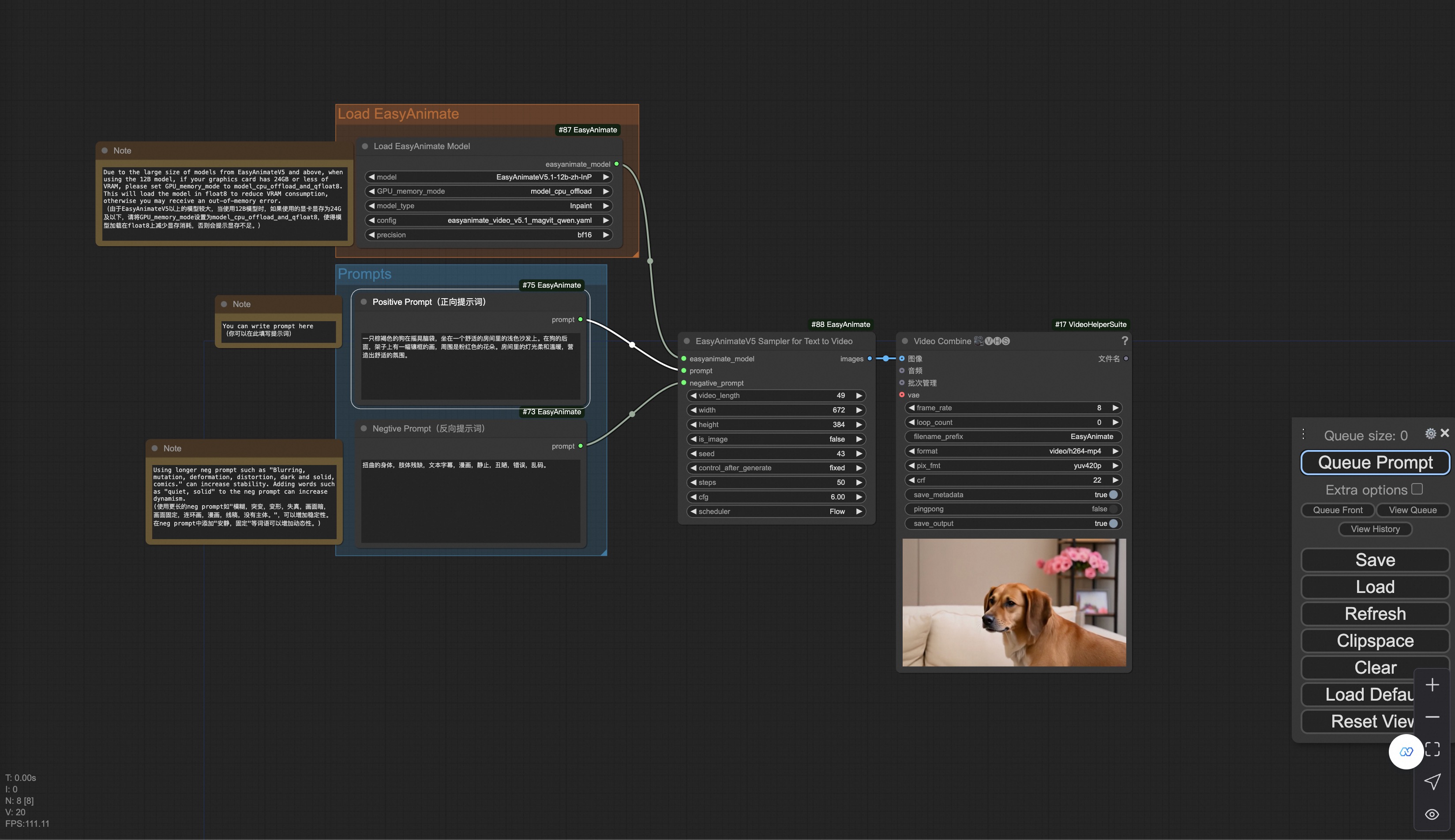
Our user interface is shown as follows, this is the json:
You can run a demo using the following photo:

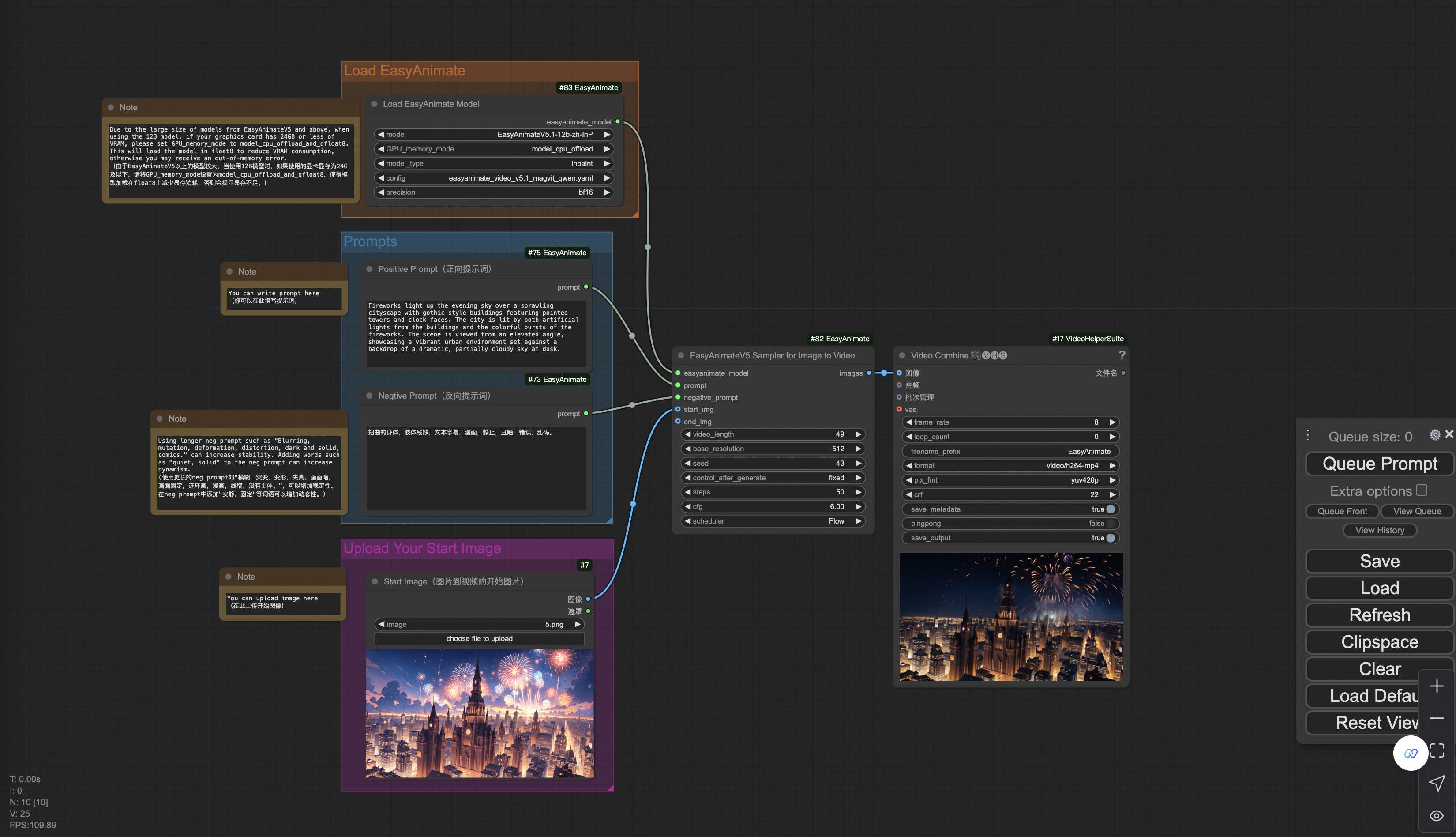
Our user interface is shown as follows, this is the json:
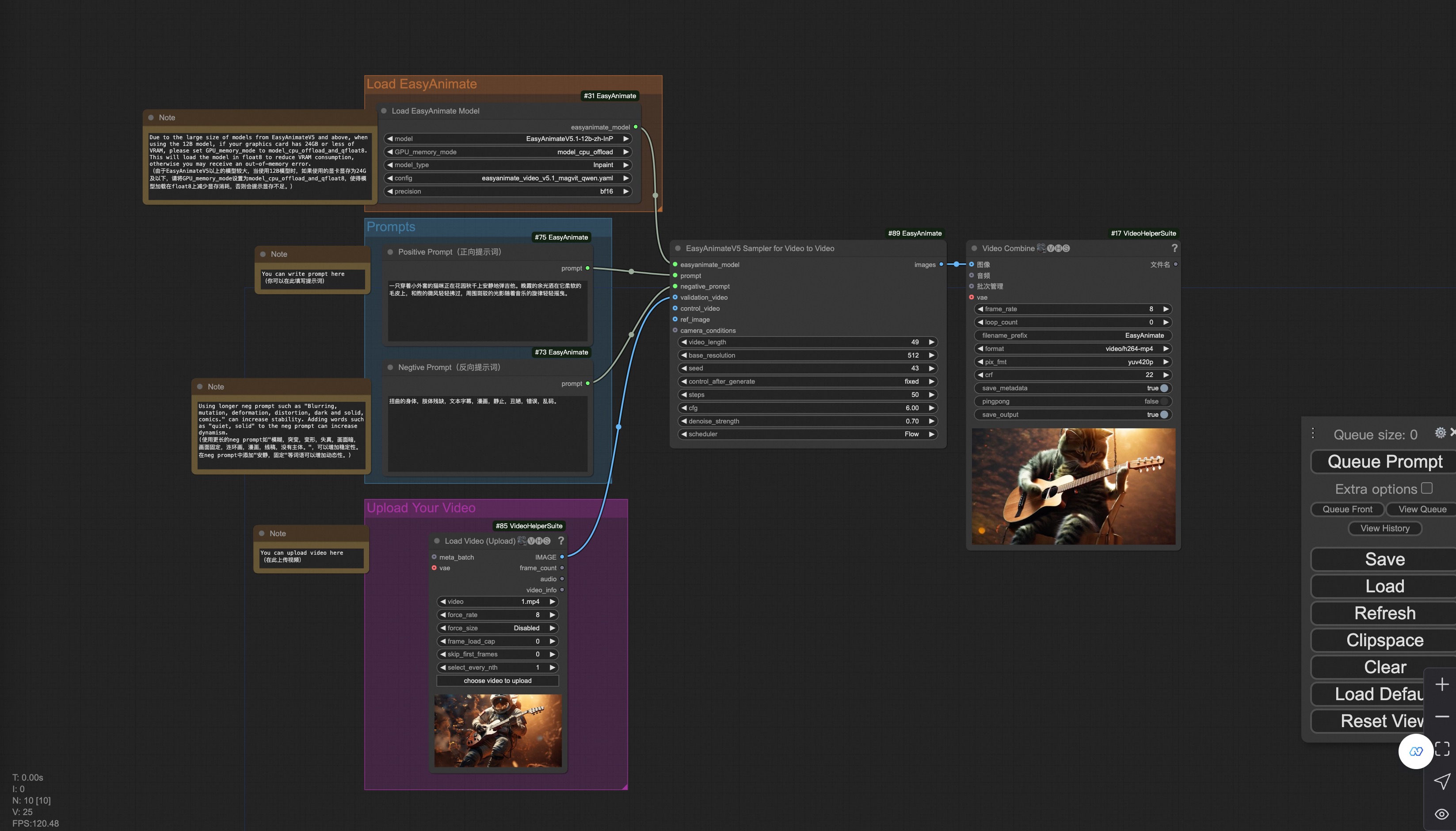
You can run a demo using the following video:
Our user interface is shown as follows, this is the json:
You can run a demo using the following photo:
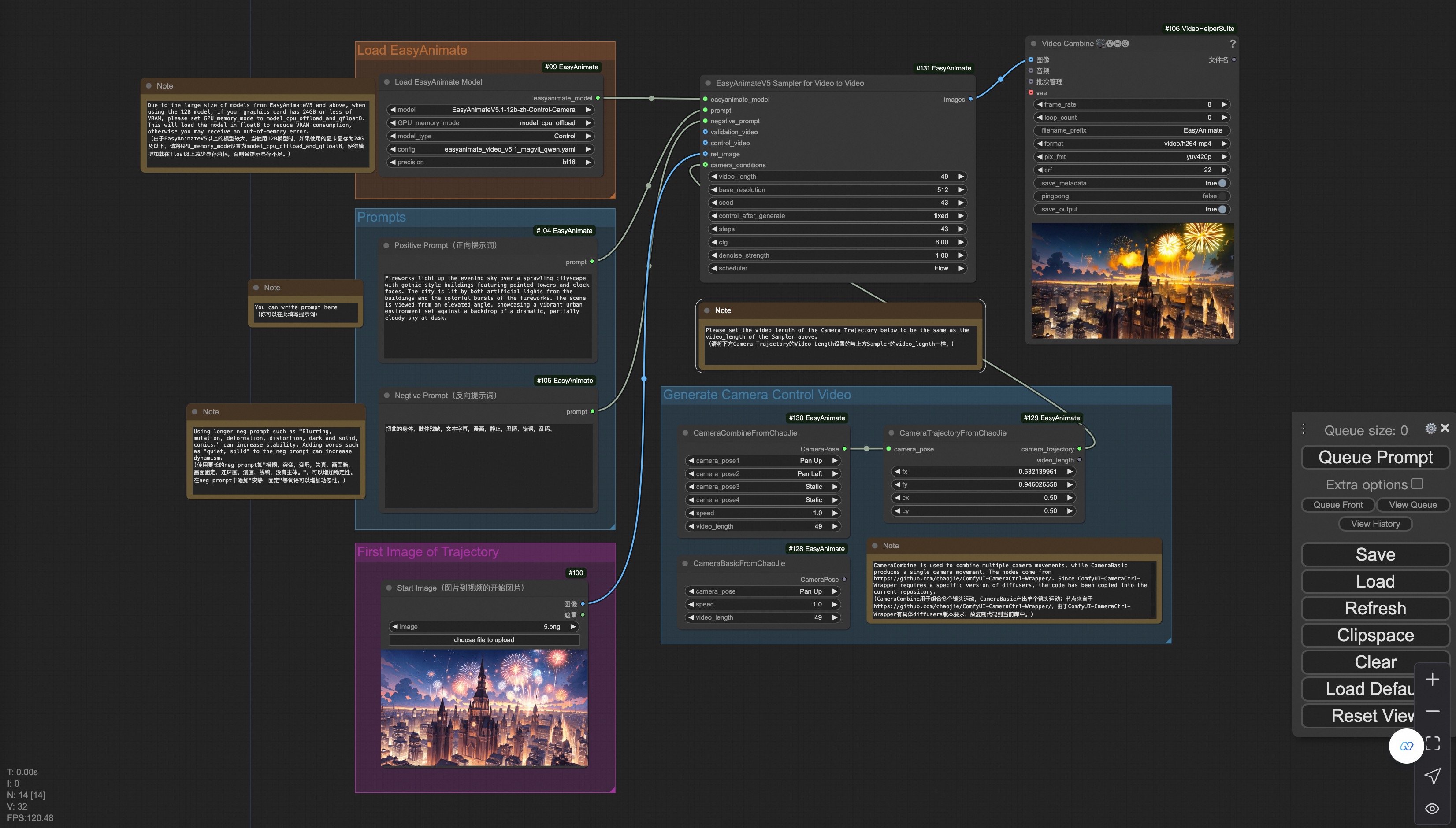
Our user interface is shown as follows, this is the json:
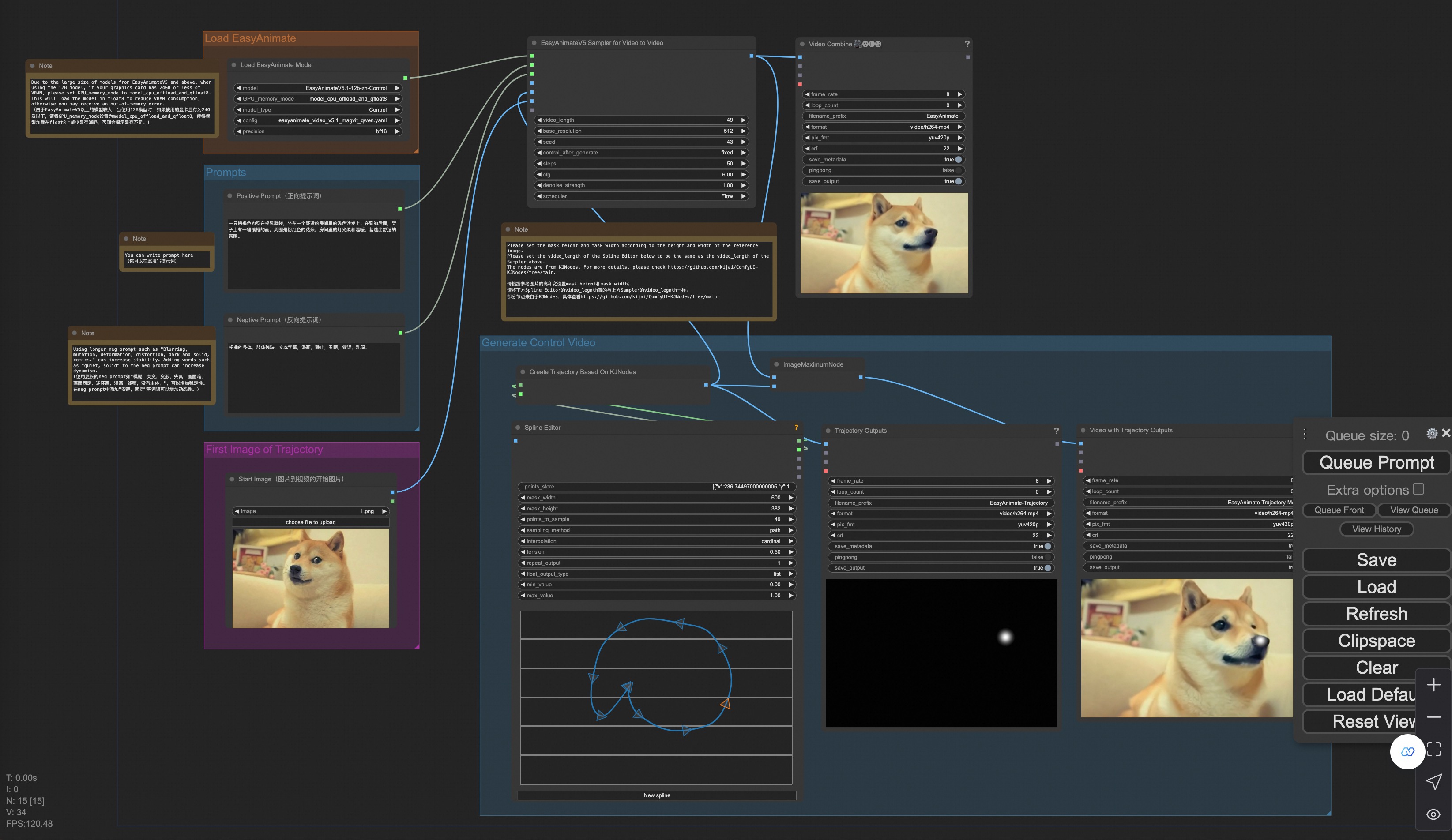
You can run a demo using the following photo:

Our user interface is shown as follows, this is the json:
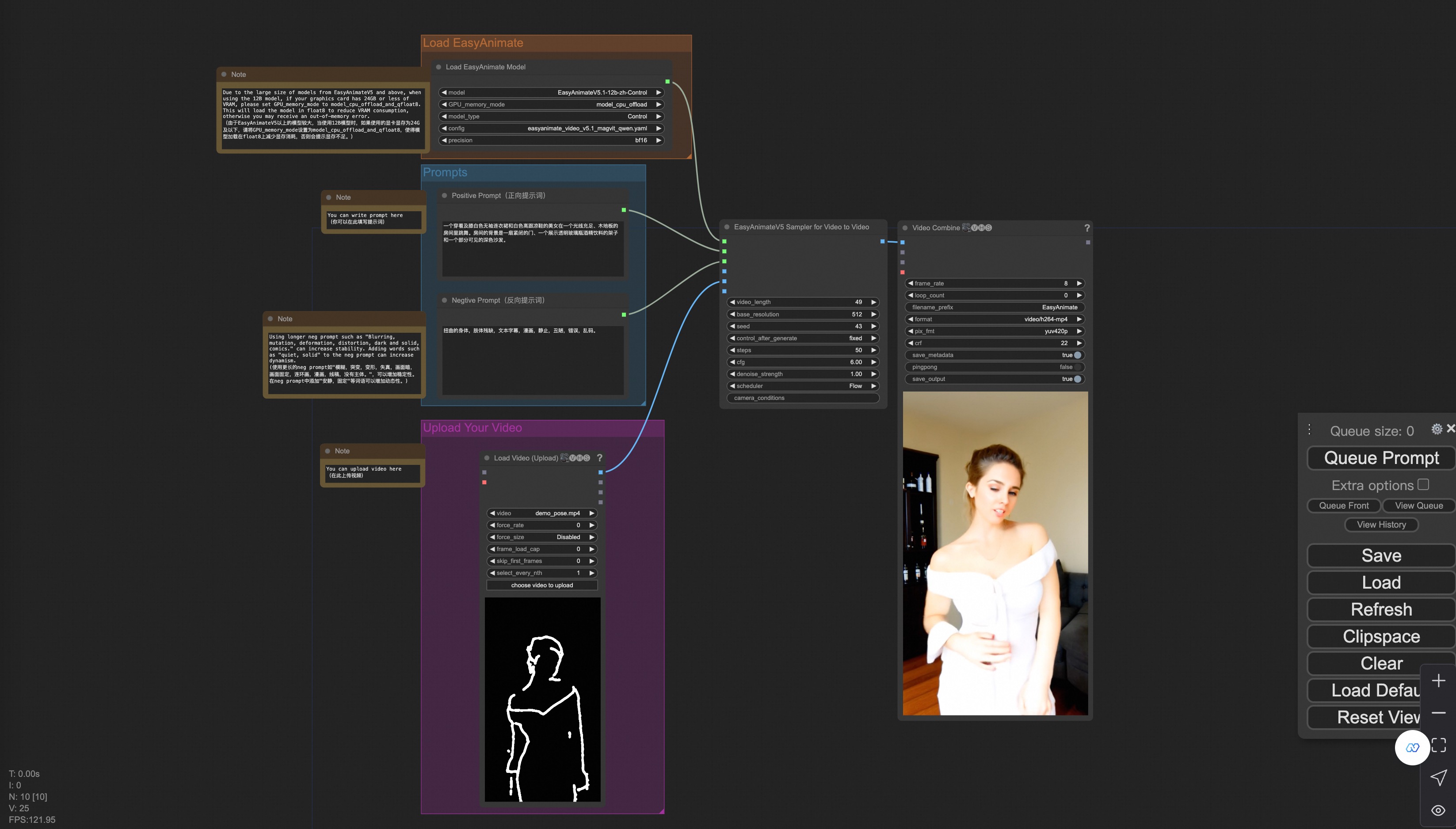
You can run a demo using the following video: