Training freezes after the first epoch #1110
Labels
stale
This issue has become stale
Comments
|
Same issue here unsolved |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
Similar issue. Can we please reopen this, @ThilinaRajapakse ? |
|
For now, this has helped me: model_args = ClassificationArgs(
use_multiprocessing=False,
use_multiprocessing_for_evaluation=False,
)
os.environ["TOKENIZERS_PARALLELISM"] = "false" |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Describe the bug
The script stucks after training the initial epoch.
To Reproduce
The original code is available on:
https://towardsdatascience.com/bart-for-paraphrasing-with-simple-transformers-7c9ea3dfdd8c
I made few modifications, so this is my code that I am trying to run:
`import os
from datetime import datetime
import logging
import pandas as pd
from sklearn.model_selection import train_test_split
from simpletransformers.seq2seq import Seq2SeqModel, Seq2SeqArgs
from data.utils import load_data, clean_unnecessary_spaces
os.environ["TOKENIZERS_PARALLELISM"] = "true"
logging.basicConfig(level=logging.INFO)
transformers_logger = logging.getLogger("transformers")
transformers_logger.setLevel(logging.ERROR)
train_df = pd.read_csv("data/train.tsv", sep="\t").astype(str)
eval_df = pd.read_csv("data/dev.tsv", sep="\t").astype(str)
train_df = train_df.loc[train_df["label"] == "1"]
eval_df = eval_df.loc[eval_df["label"] == "1"]
train_df = train_df.rename(
columns={"sentence1": "input_text", "sentence2": "target_text"}
)
eval_df = eval_df.rename(
columns={"sentence1": "input_text", "sentence2": "target_text"}
)
train_df = train_df[["input_text", "target_text"]]
eval_df = eval_df[["input_text", "target_text"]]
train_df["prefix"] = "paraphrase"
eval_df["prefix"] = "paraphrase"
train_df = pd.concat(
[
train_df,
load_data("data/msr_paraphrase_train.txt", "#1 String", "#2 String", "Quality"),
]
)
eval_df = pd.concat(
[
eval_df,
load_data("data/msr_paraphrase_test.txt", "#1 String", "#2 String", "Quality"),
]
)
df = load_data(
"data/quora_duplicate_questions.tsv", "question1", "question2", "is_duplicate"
)
q_train, q_test = train_test_split(df)
q_train = pd.read_csv("data/quora_train.tsv", sep="\t")
q_test = pd.read_csv("data/quora_test.tsv", sep="\t")
train_df = pd.concat([train_df, q_train])
eval_df = pd.concat([eval_df, q_test])
train_df = train_df[["prefix", "input_text", "target_text"]]
eval_df = eval_df[["prefix", "input_text", "target_text"]]
train_df = train_df.dropna()
eval_df = eval_df.dropna()
train_df["input_text"] = train_df["input_text"].apply(clean_unnecessary_spaces)
train_df["target_text"] = train_df["target_text"].apply(clean_unnecessary_spaces)
eval_df["input_text"] = eval_df["input_text"].apply(clean_unnecessary_spaces)
eval_df["target_text"] = eval_df["target_text"].apply(clean_unnecessary_spaces)
print(train_df)
model_args = Seq2SeqArgs()
model_args.do_sample = True
model_args.eval_batch_size = 64
model_args.evaluate_during_training = True
model_args.evaluate_during_training_steps = 2500
model_args.evaluate_during_training_verbose = True
model_args.fp16 = False
model_args.learning_rate = 5e-5
model_args.max_length = 128
model_args.max_seq_length = 128
model_args.num_beams = None
model_args.num_return_sequences = 3
model_args.num_train_epochs = 2
model_args.overwrite_output_dir = True
model_args.reprocess_input_data = True
model_args.save_eval_checkpoints = False
model_args.save_steps = -1
model_args.top_k = 50
model_args.top_p = 0.95
model_args.train_batch_size = 8
model_args.use_multiprocessing = False
model_args.wandb_project = "Paraphrasing with BART"
model = Seq2SeqModel(
encoder_decoder_type="bart",
encoder_decoder_name="facebook/bart-base",
args=model_args,
use_cuda = True,
)
train_df = train_df.sample(2000)
model.train_model(train_df, eval_data=eval_df)
to_predict = [
prefix + ": " + str(input_text)
for prefix, input_text in zip(eval_df["prefix"].tolist(), eval_df["input_text"].tolist())
]
truth = eval_df["target_text"].tolist()
preds = model.predict(to_predict)
os.makedirs("predictions", exist_ok=True)
with open(f"predictions/predictions_{datetime.now()}.txt", "w") as f:
for i, text in enumerate(eval_df["input_text"].tolist()):
f.write(str(text) + "\n\n")
`
Expected behavior
After running the code, it should generate and save a model that I can use later.
Screenshots
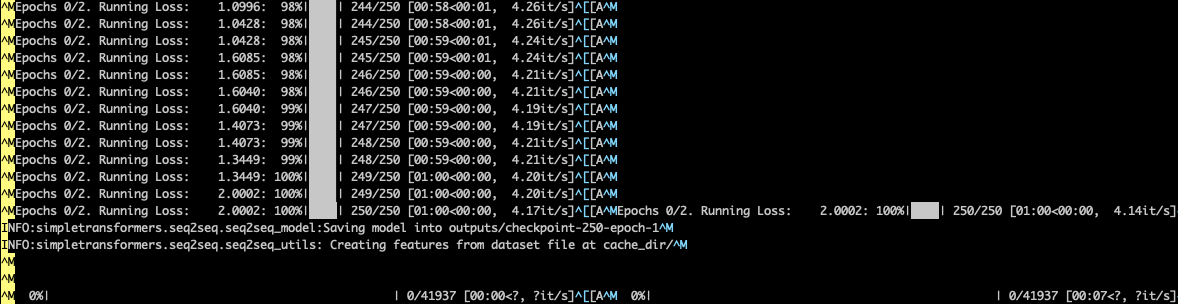
The script freezes at the point shown below:
Desktop (please complete the following information):
Additional context
This is the list of packages and their versions in the virtual env:
`Package Version
altair 4.1.0
astor 0.8.1
base58 2.1.0
blinker 1.4
cached-property 1.5.2
cachetools 4.2.1
certifi 2020.12.5
chardet 4.0.0
click 7.1.2
configparser 5.0.2
dataclasses 0.8
datasets 1.6.0
dill 0.3.3
docker-pycreds 0.4.0
filelock 3.0.12
fsspec 2021.4.0
gitdb 4.0.7
GitPython 3.1.14
h5py 3.1.0
huggingface-hub 0.0.8
idna 2.10
importlib-metadata 3.7.3
joblib 1.0.1
Keras 2.4.3
multiprocess 0.70.11.1
numpy 1.19.5
packaging 20.9
pandas 1.1.3
pathtools 0.1.2
Pillow-SIMD 7.0.0.post3
pip 20.0.2
promise 2.3
protobuf 3.15.8
psutil 5.8.0
pydeck 0.6.2
pyparsing 2.4.7
python-dateutil 2.8.1
pytz 2021.1
PyYAML 5.3.1
regex 2020.11.13
requests 2.25.1
sacremoses 0.0.45
scikit-learn 0.24.1
scipy 1.5.4
sentencepiece 0.1.91
sentry-sdk 1.0.0
seqeval 0.0.10
setuptools 46.1.3
shortuuid 1.0.1
simpletransformers 0.61.4
six 1.15.0
smmap 4.0.0
streamlit 0.80.0
subprocess32 3.5.4
tensorboardX 2.2
threadpoolctl 2.1.0
tokenizers 0.10.1
toml 0.10.2
toolz 0.11.1
torch 1.8.1
torchvision 0.9.1
tqdm 4.60.0
transformers 4.5.1
typing-extensions 3.7.4.3
tzlocal 2.1
urllib3 1.26.4
validators 0.18.2
wandb 0.10.27
watchdog 0.10.4
wheel 0.34.2
xxhash 2.0.0
zipp 3.4.1
arrow 2.0.0`
The text was updated successfully, but these errors were encountered: