First, a brief introduction of what the Fourier Transform is and how we get to the Fast Fourier Transform, the practical application of the transform. If you are familiar with fourier transforms, you can safely skip this section. Don't expect rigorous derivations of the transform, there are plenty of resources online explaining the fourier transform.
The Fourier Transform is a mathematical transform which converts time-domain signals into the frequency domain (and back, as we will see later). Related transforms are the discrete cosine transform (DCT) and discrete sine transform (DST) which do essentially the same thing. Especially DCT has enjoyed extensive use in audio, image and video compression over the last decades.
The original definition of the fourier transform is an infinite integral. The main idea is that all signals can be expressed as sum of infinite number of sinusoids and we can find the sinusoid frequency components with the transform:
X(w) = integrate from -inf to +inf: x(t)exp(-iwt) dt
where w is angular frequency 2 * pi * frequency and i is the imaginary constant.
To recap imaginary numbers, they are two-dimensional numbers which consist of a real part, and an imaginary part.
c = a + ib
The imaginary constant is defined as sqrt(-1). Arithmetic with it is fairly obvious.
(a + ib) + (c + id) = a + c + i(b + d)
(a + ib) - (c + id) = a - c + i(b - d)
(a + ib) * (c + id) = ac + ib + id + i^2 bd = ac - bd + i(b + d)
The conjugate is a common operation. It simply flips the sign of the imaginary component. It's often noted with trailing asterisk.
(a + ib)* = a - ib
Complex exponentials are fairly interesting. We have Taylor expansions of some trancendental functions.
exp(x) = 1 + x/1! + x^2/2! + x^3/3! + x^4/4! + ...
cos(x) = 1 - x^2/2! + x^4/4! - x^6/6! + ...
sin(x) = x - x^3/3! + x^5/5! - x^7/7! + ...
By working out the taylor expansions for exp(ix) we find an interesting result ...
exp(ix) = cos(x) + isin(x)
exp(-ix) = cos(x) - isin(x) = exp(ix)*
Basically, the complex exponential is a complex valued oscillator. This makes sense, since the fourier transform is essentially correlating the input signal against various oscillators, which allows us to extract frequency components. Complex oscillators can distinguish between positive frequencies and negative frequencies (which will become relevant in a bit), but other than that they're pretty much ye olde sinusoids.
To make the fourier transform practical, we need to assume that our signal is repeating in some way. Lets assume we have a signal x(t) defined from t = 0 to T. x(t + T) = x(t). It is fairly easy to show that we can now only have frequencies which are a multiple of (1 / T) in our signal. If we try to reconstruct the repeating x(t) pattern using sinusoids, we must use sinusoids which also repeat in the same pattern, i.e. frequencies multiple of 1 / T.
The final change to make things computable is to make our time domain discrete as well (i.e. sampling). When we make the time domain discrete we repeat the frequency spectrum with a period of (1 / sampling interval). If our sampling interval is D, we get aliasing where
X(w) = X(w + 2 * pi * (1 / D))
If you know your Nyquist you might be confused because you know that the maximum reconstructible frequency is (sampling frequency / 2) and not (sampling frequency), but don't fear. Let's assume sampling interval is 1 s, i.e. 1 Hz and we sample a signal that is 0.6 Hz.
X(2 * pi * 0.6) = X(2 * pi * (-0.4))
The 0.6 Hz component is aliased into -0.4 Hz (negative frequency). We can think of our repeated frequency spectrum as [0, 1/D] or [-0.5/D, +0.5/D], the end result is the same. For real input signals negative and positive frequencies are pretty much the same thing (just inverted phase), so we rarely consider negative frequencies but they are distinct for complex signals.
Once we have made the signal repeating and made time discrete, we are now ready for our fourier transform since we have a finite number of frequencies (well, infinite, but the frequency components repeat due to aliasing so we don't care) in our signal.
Recall the integral
X(w) = integrate from -inf to +inf: x(t)exp(-iwt) dt
Since we made the signal repeating, we change it to a bounded integral
X(w) = integrate from 0 to T: x(t)exp(-iwt) dt
And since we made time discrete we can change the integral to a discrete sum:
X(2 * pi * k / T) = sum n from 0 to T / D - 1:
x(n * D) * exp(-i * (2 * pi * k / T) * (n * D)) = x(n * D) * exp(-i * 2 * pi * k * n * D / T)
T / D is the number of samples we have in our repeating signal, let's call it N to make it clearer and let's call make our sampled input signal an array, x[n] = x(n * D). Finally, we only have N different frequencies due to our repeating spectrum, where k = [0, N - 1], so let's make that an array as well, X[k] = X(2 * pi * k / T).
X[k] = sum n from 0 to N - 1: x[n] * exp(-i * 2 * pi * k * n / N)
And there we have it, the Discrete Time Fourier Transform.
Going from frequency domain to time domain is very similar, we only need to slightly alter the formula. Note that the phase of the exponential is inverted, otherwise the math looks very similar (the same).
x[n] = sum k from 0 to N - 1: (1 / N) * X[k] * exp(+i * 2 * pi * k * n / N)
The 1 / N term here is just a normalization factor. It is also needed in the continous time transform, but it was omitted intentionally. muFFT omits this normalization step. We don't always care about every coefficient being scaled.
A big problem with the naive DFT algorithm is its complexity. To evaluate every frequency coefficient, we need O(n^2) operations, fortunately there are more efficient ways of doing this which algorithm is called the fast fourier transform (duh).
The DFT represents the strength of each frequency component in the input signal as well as its phase. Both phase and amplitude are neatly encoded in a single complex number (one reason why complex numbers are so vitally important to any math dealing with waves of sorts!)
Every amplitude with angle can be expressed as a complex number
ComplexNumber(amplitude, phase) = amplitude * exp(+i * phase)
By far, the most common input data to the fourier transform is real input data. Note that the definition of the fourier transform allows x[n] to be complex, but we will see that there are some redundancies in the DFT when x[n] is real.
X[k] = sum n: x[n] * exp(-i * 2 * pi * k * n / N)
X[N - k] = sum n: x[n] * exp(-i * 2 * pi * (N - k) * n / N)
= sum n: x[n] * exp(-i * 2 * pi * -k * n / N) * exp(-i * 2 * pi * N / N)
= sum n: x[n] * exp(-i * 2 * pi * -k * n / N) * 1
= sum n: x[n] * exp(+i * 2 * pi * k * n / N)
= (sum n: x[n] * exp(-i * 2 * pi * k * n / N))*
= (X[k])* // This only works because x[n] is real because x[n]* = x[n]!
= X[k]*
And we have an interesting result. The frequency components are perfectly mirrored around X[N / 2] except for the trivial change that the frequency component is conjugated.
We only really need to compute X[0] up to and including X[N / 2]. Due to the symmetry
X[N / 2] = X[N / 2]*
X[N / 2] must be real as well, but this is a minor point.
The Fast Fourier Transform is an optimization which allows us to get O(nlogn) performance rather than DFT O(n^2).
This optimization is realized by finding some recursive patterns in the computation. First, let's have a quick look at the DFT formula again.
X[k] = sum n: x[n] * exp(-i * 2 * pi * k * n / N)
Writing the full exponential gets a bit annoying so let
W(x, N) = exp(-i * 2 * pi * x / N)
so that we can rewrite the sum as
X[k] = sum n: x[n] * W(k * n, N)
Lets split this sum into even n and odd n
X[k] = sum n: x[2n] * W(k * 2n, N) + x[2n + 1] * W(k * (2n + 1), N)
Since W(k + 1, N) = W(k, N) * W(1, N), we can factor out some stuff
X[k] = sum n: x[2n] * W(k * 2n, N) + W(k, N) * x[2n + 1] * W(k * n, N / 2)
= sum n: x[2n] * W(k * n, N / 2) + W(k, N) * x[2n + 1] * W(k * n, N / 2)
= Xeven[k] + W(k, N) * Xodd[k]
Some interesting things happen if we try X[k + N / 2]
X[k + N / 2]
= sum n: x[2n] * W((k + N / 2) * n, N / 2) + W((k + N / 2), N) * x[2n + 1] * W((k + N / 2) * n, N / 2)
= sum n: x[2n] * W(k * n, N / 2) - W(k, N) * x[2n + 1] * W(k * n, N / 2)
= Xeven[k] - W(k, N) * Xodd[k]
All the exponentials either repeat themselves or simply invert. We can now essentially compute two frequency samples by taking two smaller DFTs and either add or subtract the right hand side.
This definition is recursive as well. We can keep splitting Xeven and Xodd into even and odd DFTs and do this same optimization over and over until we end up with a N = 2 DFT. This assumes that the transform size is power-of-two which is often a reasonable assumption. Note that it is possible to split into any factor you want, every third, every fourth, every fifth and so on, and the math will look very similar.
Let's try to illustrate this for a DFT of length 8.

If we complete the recursion, we get a structure looking like this:

This structure is called the Radix-2 decimation-in-time (DIT) algorithm.
The pattern created by the computation is quite pleasing. The computational pattern is
a' = a + W * b
b' = a - W * b
Writing it out on paper obtains a pattern which is called the butterfly.
a and b are updated in place in this structure.
A common terminology in FFTs are the twiddle factors. The twiddle factors are the W(k, N) factors we multiply Xodd[k] with before doing a butterfly step with Xeven[k].
As you can see from the DIT illustration, the input data has been reordered. The pattern here is that the input data indices have been sorted with reversed bit order.
000 (0) -> 000 (0)
001 (1) -> 100 (4)
010 (2) -> 010 (2)
011 (3) -> 110 (6)
100 (4) -> 001 (1)
101 (5) -> 101 (5)
110 (6) -> 011 (3)
111 (7) -> 111 (7)
If we want to compute our DIT FFT in place, we would have to do this reordering step before computing the FFT.
The DIF structure is very similar to DIT. The biggest difference is that the butterfly stages come in reverse order compared to DIT. The twiddle factors are multiplied in after the butterfly and not before as with DIT. It's easy to show that the DIF perfectly cancels out everything a DIT structure would do if the twiddle factors are conjugated (only difference between inverse and forward FFT), and therefore it's also a perfectly valid FFT implementation. The main difference is that instead of getting reordered input, we get reordered output instead, which is sometimes more desirable.
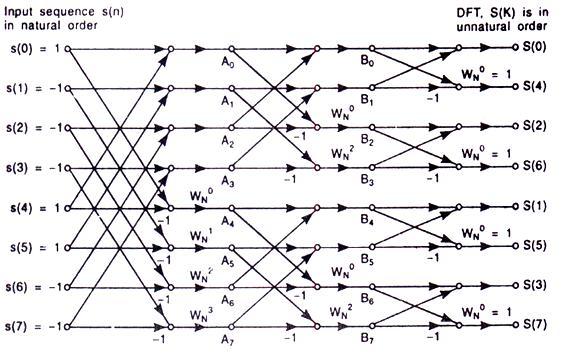
If we can help it, we'd like to avoid extra reordering steps. We want ordered input and ordered output. It turns out we can by making use of an extra buffer during computation of the FFT. We cannot do this computation in-place since butterfly steps are not written back to the same indices they were read from.
Eric Bainville's FFT page has a good illustration of how the Stockham autosort works and how it's implemented in a radix-2 algorithm. Input data is always read just like the first stage of the DIF algorithm, but it is written out to different places every time. The result is that the input indices are reordered one bit at a time for every stage.
muFFT implements this scheme. It is very SIMD-friendly and can easily be extended to radix-4, radix-8 and beyond.
The Radix-2 formulation itself is fine, but it is not very efficient. On modern hardware architectures we want to do as much useful computation on the data we load as possible before writing it back out again. A Radix-2 implementation does very little work (just a twiddle complex multiply and butterfly) before writing back results to memory and if we only rely on a radix-2 implementation, we quickly find that we're not limited on arithmetic throughput of the architecture. There are also few possibilities to obtain decent instruction level parallelism which is vital to fully utilize modern heavily pipelined architectures.
To improve this, we need to do multiple FFT stages in one pass in order to have more work in flight. We can do two radix-2 butterflies in one pass to obtain radix-4 and three radix-2 butterflies to get radix-8. muFFT implements radix-4 and radix-8 as well as radix-2. In theory we can keep increasing the radix like this, but eventually we run out of work registers.
A non-obvious application of the FFT is linear convolution. The convolution is often used to apply filters to audio.
y[n] = conv(x, h) = sum i from -inf to +inf: x[n - i] * h[i]
In reality, x[n] and h[n] are not infitely long so the sum becomes bounded. Convolution like this takes order O(N * M) where N is length of x and M is length of h. For very long filters, straight convolution becomes impractical.
When we do a convolution, what we're essentially doing is to apply a frequency response. In the frequency domain, we're simply multiplying. What we can do instead is
y[n] = (1 / N) * IFFT(FFT(x) .* FFT(h))
where .* denotes element-wise multiplication. The lengths of x and h here must be the same, but we can simply zero-pad at the end of either array to get this.
Instead of O(N^2) for the convolution we now have order O(3NlogN + N).
The normalization faction 1 / N mentioned earlier now becomes rather important, so we add that in as well.
Note that the FFT convolution is circular, since the very definition we have for the FFT assumes that the signal is indeed circular. If length of x is N and h is M, the length of the convolution becomes N + M - 1. We therefore need an FFT which is at least this size to avoid wrapping errors. We round this value up to power-of-two, and zero pad x and h at the end up to this new FFT size.
A very common operation in audio processing is to convolve two arrays of equal power-of-two length, say N. We need FFT of 2 * N - 1, but we round this up to 2 * N. We zero pad x and h with arrays of length N and do our FFT convolution.
Since this exact pattern for zero-padding is so common, muFFT have options which lets the FFT transform assume that you have zero padded the upper half of the array. There is no need to copy your data over to a zero padded array first.
Real-to-complex transforms and back can always be expressed using complex-to-complex transforms, but we are doing lots of redundant work in this case since the imaginary component of the input is always 0. In theory we can save roughly half the work by assuming the input data is always real.
This page explains how we can treat a real transform of N samples as a complex N / 2 sample transform by adding a simple butterfly stage at the end. We can also turn a complex-to-real transform of size into a regular inverse N / 2 complex transform by doing a simple radix-2 DIF butterfly stage.
If we have two independent real signals (e.g. stereo audio), we can treat the left and right channels as a combined complex signal
s[n] = l[n] + ir[n]
Notice that if we use the interleaved complex format of (real, imag, real, imag), regular interleaved stereo audio samples fit perfectly into this model already! If we take the FFT, we get
S[k] = L[k] + iR[k]
We can now do a convolution with a real valued filter h[n], which is a very common operation in audio processing:
H[k] = h[n]
S'[k] = (L[k] + iR[k]) * H[k]
= L[k]H[k] + iR[k]H[k]
s'[n] = l'[n] + ir'[n]
If we now take the inverse transform, we know that IFFT(L * H) is purely real, and IFFT(R * H) is purely real. i * IFFT(R * H) is therefore purely imaginary, and therefore completely orthogonal to IFFT(L * H) which is purely real. The left channel will be the real part of the filtered signal and the right channel will be the imaginary part of the filtered signal, which is exactly what we wanted to have since interleaved stereo samples are so common.
muFFT implements all of these schemes in its convolution module as well as the real-to-complex and complex-to-real 1D transforms.