In this we explore the large language models like Pegasus ,ERNIE and T5 Large
Introduction ERNIE 2.0 is a continual pre-training framework proposed by Baidu in 2019, which builds and learns incrementally pre-training tasks through constant multi-task learning. Experimental results demonstrate that ERNIE 2.0 outperforms BERT and XLNet on 16 tasks including English tasks on GLUE benchmarks and several common tasks in Chinese.
More detail: Link
Released Model Info This released pytorch model is converted from the officially released PaddlePaddle ERNIE model and a series of experiments have been conducted to check the accuracy of the conversion.
Official PaddlePaddle ERNIE repo:Repo
Pytorch Conversion repo:Repo
How to use
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nghuyong/ernie-2.0-base-en")
model = AutoModel.from_pretrained("nghuyong/ernie-2.0-base-en")Citation
@article{sun2019ernie20,
title={ERNIE 2.0: A Continual Pre-training Framework for Language Understanding},
author={Sun, Yu and Wang, Shuohuan and Li, Yukun and Feng, Shikun and Tian, Hao and Wu, Hua and Wang, Haifeng},
journal={arXiv preprint arXiv:1907.12412},
year={2019}
}

A continual pre-training framework named ERNIE 2.0 is proposed, which incrementally builds pre-training tasks and then learn pre-trained models on these constructed tasks via continual multi-task learning.

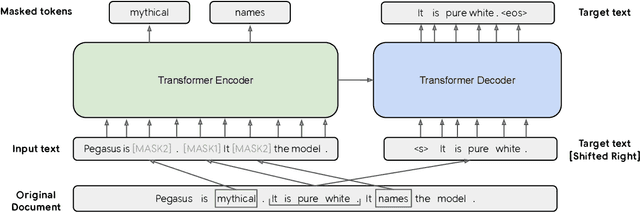
Image taken from Medium.com
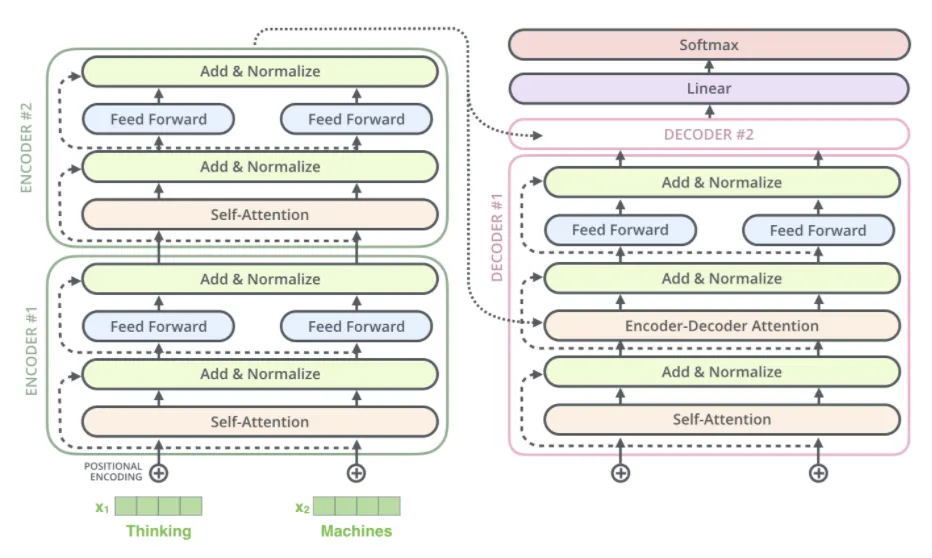
The model is a standard Transformer encoder. Task embedding is introduced to represent the characteristic of different tasks. Each task has an unique id ranging from 0 to N.
Later, ERNIE 3.0 is also proposed.
The PEGASUS-X model that is adapted for long input summarization.
The PEGASUS-X model is described in Investigating Efficiently Extending Transformers for Long Input Summarization.
To convert PEGASUS TensorFlow checkpoints for use with the Flax code, use the script convert_from_pegasus_to_flax.
You will also need to download the tokenizer file from here.
The full set of available checkpoints can be found in the PEGASUS GCS Bucket.
We highlight the notable PEGASUS-X-specific checkpoints here:
-
PEGASUS-X-base (272M):
-
PEGASUS-X (568M):
- PEGASUS-X (adapted but not fine-tuned)
- Fine-tuned on arXiv
- Fine-tuned on Big Patent
- Fine-tuned on PubMed
- Fine-tuned on GovReport (SCROLLS)
- Fine-tuned on QMSum (SCROLLS)
- Fine-tuned on SummScreen/FD (SCROLLS)
T5 (Text-to-Text Transfer Transformer) is a series of large language models developed by Google AI. Introduced in 2019,T5 models are trained on a massive dataset of text and code using a text-to-text framework. The T5 models are capable of performing the text-based tasks that they were pretrained for. They can also be finetuned to perform other tasks.They have been employed in various applications, including chatbots, machine translation systems, text summarization tools, code generation, and robotics.
To know more about it visit github
It was source from source
Baseline model for the T5 Framework is
It was source from paper