A library for the simple visualization of different types of Spark NLP annotations.
- Dependency Parser
- Named Entity Recognition
- Entity Resolution
- Relation Extraction
- Assertion Status
https://github.com/JohnSnowLabs/spark-nlp-display/blob/main/tutorials/Spark_NLP_Display.ipynb
- spark-nlp
- ipython
- svgwrite
- pandas
- numpy
pip install spark-nlp-displayFor all modules, pass in the additional parameter "return_html=True" in the display function and use Databrick's function displayHTML() to render visualization as explained below:
from sparknlp_display import NerVisualizer
ner_vis = NerVisualizer()
## To set custom label colors:
ner_vis.set_label_colors({'LOC':'#800080', 'PER':'#77b5fe'}) #set label colors by specifying hex codes
pipeline_result = ner_light_pipeline.fullAnnotate(text) ##light pipeline
#pipeline_result = ner_full_pipeline.transform(df).collect()##full pipeline
vis_html = ner_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
label_col='entities', #specify the entity column
document_col='document', #specify the document column (default: 'document')
labels=['PER'], #only allow these labels to be displayed. (default: [] - all labels will be displayed)
return_html=True)
displayHTML(vis_html)
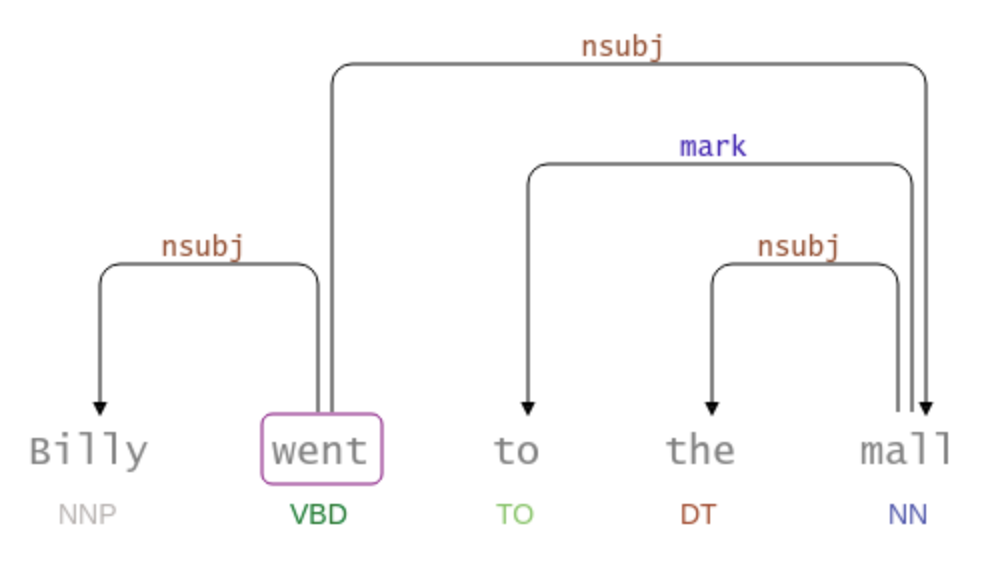
from sparknlp_display import DependencyParserVisualizer
dependency_vis = DependencyParserVisualizer()
pipeline_result = dp_pipeline.fullAnnotate(text)
#pipeline_result = dp_full_pipeline.transform(df).collect()##full pipeline
dependency_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe.
pos_col = 'pos', #specify the pos column
dependency_col = 'dependency', #specify the dependency column
dependency_type_col = 'dependency_type' #specify the dependency type column
)
from sparknlp_display import NerVisualizer
ner_vis = NerVisualizer()
pipeline_result = ner_light_pipeline.fullAnnotate(text)
#pipeline_result = ner_full_pipeline.transform(df).collect()##full pipeline
ner_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
label_col='entities', #specify the entity column
document_col='document' #specify the document column (default: 'document')
labels=['PER'] #only allow these labels to be displayed. (default: [] - all labels will be displayed)
)
## To set custom label colors:
ner_vis.set_label_colors({'LOC':'#800080', 'PER':'#77b5fe'}) #set label colors by specifying hex codes
from sparknlp_display import EntityResolverVisualizer
er_vis = EntityResolverVisualizer()
pipeline_result = er_light_pipeline.fullAnnotate(text)
er_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
label_col='entities', #specify the ner result column
resolution_col = 'resolution'
document_col='document' #specify the document column (default: 'document')
)
## To set custom label colors:
er_vis.set_label_colors({'TREATMENT':'#800080', 'PROBLEM':'#77b5fe'}) #set label colors by specifying hex codes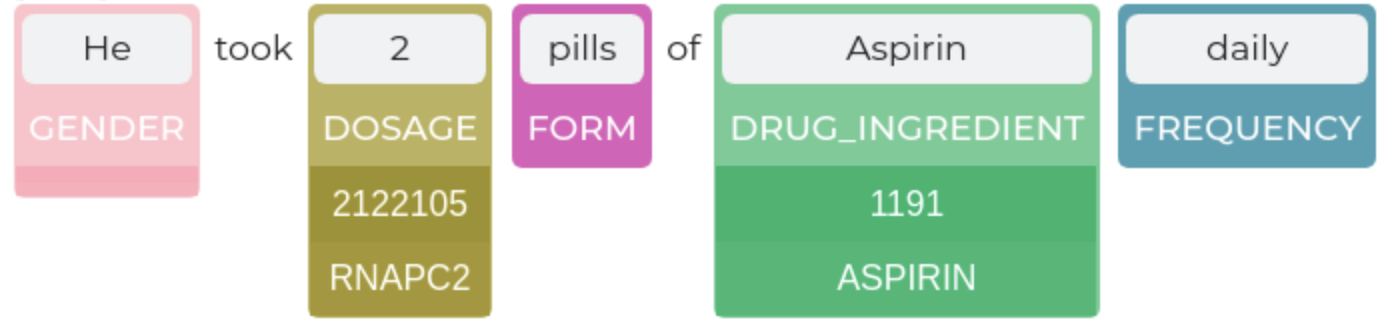
from sparknlp_display import RelationExtractionVisualizer
re_vis = RelationExtractionVisualizer()
pipeline_result = re_light_pipeline.fullAnnotate(text)
re_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
relation_col = 'relations', #specify relations column
document_col = 'document', #specify document column
show_relations=True #display relation names on arrows (default: True)
)
from sparknlp_display import AssertionVisualizer
assertion_vis = AssertionVisualizer()
pipeline_result = ner_assertion_light_pipeline.fullAnnotate(text)
assertion_vis.display(pipeline_result[0],
label_col = 'entities', #specify the ner result column
assertion_col = 'assertion' #specify assertion column
document_col = 'document' #specify the document column (default: 'document')
)
## To set custom label colors:
assertion_vis.set_label_colors({'TREATMENT':'#008080', 'problem':'#800080'}) #set label colors by specifying hex codes