虚拟内存的目的是为了让物理内存扩充为更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成了地址空间。每个程序都拥有自己的地址空间,这个地址空间被分割成了多个块,每一块称为一页。
这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有的页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存中并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说,一个程序不需要全部调入内存就可以运行了,这样使得有限的内存运行大程序成为了可能。
例如现在有一台计算机可以产生16位的地址,那么一个程序的地址空间范围是0~64K(2^16=65536=64K),该计算机只有32KB的物理内存,虚拟内存技术允许该计算机运行一个64K大小的程序。

内存管理单元(MMU)管理者地址空间和物理内存的转换,其中的页表(Page Table)存储着页(程序地址空间)和页框(物理地址空间)的映射表。
一个虚拟地址分为两个部分,一部分存储页面号,一部分存储偏移量。
下面的页表存放着16个页,这16个页需要用4个比特位来进行索引定位(0000-1111)。例如对于虚拟地址(0010 000000000100),前4位是0010代表着存储页面号为2,读取表项内容为(110 1),页表项的最后一位(1)表示是否存在于内存中,1表示存在。后12位存储pianyiliang.zhege页对应的页框的地址为(110 000000000100)

在程序运行过程中,如果要访问的页面不存在内存中,就发生断页中断从而将该页调入内存中,此时如果内存已无空闲空间,那么系统必须从内存中调出一个页面到磁盘对换区中腾出空间。
页面置换算法和缓存淘汰策略相类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的的主要目标是使得页面置换频率最低(也可以说是缺页率最低)
OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
举个栗子:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长(soga~)
LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU将最近最久未使用的页面换出。
为了实现LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移动到链表表头。这样就能保证链表尾部的页面是最近最久未访问的。
不过,这种方法每次访问都需要更新链表,因此这种方式实现的LRU代价很高。

NRU, Not Recently Used
每个页面都有两个状态位:R和M,在页面被访问时设置页面的R=1,当页面被修改时设置M=1.其中R位会定时被清零。可以将页面分为以下四类:
- R=0,M=0
- R=0,M=1
- R=1,M=0
- R=1,M=1
当发生缺页中断时,NRU算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU有限换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
FIFO, First In First Out
选择换出的页面是最先进入的页面。
该算法会将那些经常被访问的页面也被换出,从而使缺页率升高。
FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问题,对该算法做一个简单的修改:
当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。

Clock
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。

其核心思想是使用一个Map来保存数据包使用双向链表来维持顺序--它是将插入的每一条记录都包装成一个节点,每个节点包含两个其他节点的因用欧冠,一个指向前一个节点,另一个指向后一个节点。

其中Node的数据结构为:
class CacheNode {
Object key;
Object value;
CacheNode prev;
CacheNode next;
CacheNode() {
}
}
完整程序如下:
package LRU;
import java.util.concurrent.ConcurrentHashMap;
public class LRU_1 {
//缓存的数量限制
private int cacheSize;
//当前的缓存数量
private int currentSize;
//所有节点,使用线程安全的Map
private ConcurrentHashMap nodes;
//头节点
private CacheNode last;
//尾节点
private CacheNode first;
//双向链接节点
class CacheNode {
Object key;
Object value;
//前一个节点
CacheNode prev;
//后一个节点
CacheNode next;
CacheNode() {
}
}
public LRU_1(int size) {
this.cacheSize = size;
this.currentSize = 0;
nodes = new ConcurrentHashMap(size);
}
//插入数据
public void put(Object key, Object value) {
//先查询是否已存在该key,存在的话更新value,不存在的话创建一个Node并插入链表
CacheNode node = (CacheNode) nodes.get(key);
if (node == null) {
node = new CacheNode();
}
node.key = key;
node.value = value;
//若缓存已满则删除末端节点
if (currentSize >= cacheSize && last != null) {
removeLast();
}
if (currentSize == 0) {
//若只有一个节点,该节点即是头也是尾
last = node;
first = node;
} else {
node.next = first;
first.prev = node;
first = node;
}
currentSize ++;
nodes.put(key, node);
}
//查询数据@key
public Object get(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
if (node != null) {
//查询成功后将该节点移到链表头部
moveToHead(node);
return node;
}
return null;
}
//移除数据@key
public void remove(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
System.out.println("remove:node = " + node.value);
//System.out.println("remove:node.prev = " + node.prev.value);
//System.out.println("remove:node.next = " + node.next.value);
if (node != null) {
if (currentSize == 1) {
//若只有一条数据,不需要维护链表,直接清空即可
clear();
} else {
if (node == first) {
//移除的是头节点
if (node.next != null) node.next.prev = null;
first = node.next;
node.next = null;
} else if (node == last) {
//移除的是尾节点
if (node.prev != null) node.prev.next = null;
last = node.prev;
node.prev = null;
} else {
//移除的是中间的节点
node.prev.next = node.next;
node.next.prev = node.prev;
node.prev = null;
node.next = null;
}
currentSize --;
nodes.remove(key);
}
}
}
public void clear() {
nodes.clear();
}
//移除末端节点
public void removeLast() {
System.out.println("removeLast:last = " + last.value);
Object obj = nodes.remove(last.key);
if (obj != null) currentSize --;
if (last != null) {
if (last.prev != null)last.prev.next = null;
last = last.prev;
//last.prev = null;
}
}
//将最近访问的节点@node移到链表头部
public void moveToHead(CacheNode node) {
System.out.println("moveToHead:node = " + node.value);
//System.out.println("moveToHead:node.prev = " + node.prev.value);
//System.out.println("moveToHead:node.next = " + node.next.value);
if (node == first) return;
if (node == last) {
//将尾节点移到头部
node.prev.next = null;
last = node.prev;
node.prev = null;
node.next = first;
first.prev = node;
first = node;
} else {
//将中间节点移到头部
node.prev.next = node.next;
node.next.prev = node.prev;
node.prev = null;
node.next = first;
first.prev = node;
first = node;
}
}
//查看链表数据
public String toString() {
StringBuilder sb = new StringBuilder();
for (CacheNode node = first; node != null; node = node.next) {
sb.append(node.key).append(" " + node.value).append("\n");
}
return sb.toString();
}
}实例如下:
package LRU;
public class Test_1 {
public static void main(String[] args) throws Exception {
testLru();
}
private static void testLru() {
LRU_1 lruCache = new LRU_1(3 );
lruCache.put("key1", "1");
lruCache.put("key2", "2");
lruCache.put("key3", "3");
System.out.println(lruCache.toString());
lruCache.put("key4", "4");
System.out.println(lruCache.toString());
lruCache.get("key3");
System.out.println(lruCache.toString());
lruCache.remove("key4");
System.out.println(lruCache.toString());
lruCache.put("key5", "5");
System.out.println(lruCache.toString());
}
}输出为:
key3 3
key2 2
key1 1
removeLast:last = 1
key4 4
key3 3
key2 2
moveToHead:node = 3
key3 3
key4 4
key2 2
remove:node = 4
key3 3
key2 2
key5 5
key3 3
key2 2
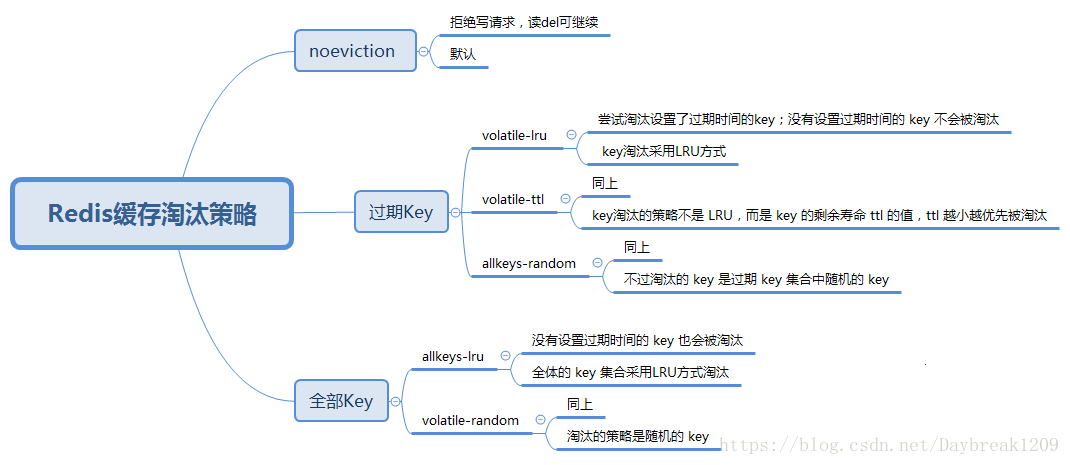
redis作为其独特之处在于它将数据放在了内存之中,大大地提高了速度。但同时带来了一个问题,往往内存大小有限,当内存剩余空间不足以继续添加数据时,redis内就会实行数据淘汰策略,清楚一部分内容来保证新的数据可以保存到内存中。
内存淘汰机制是为了更好的使用内存,用一定的miss来换取内存的利用率,保证redis缓存保存的都是热点数据。
要实行淘汰机制首先需要对redis进行相关配置。
我们可以通过配置redis conf中的maxmemory这个值来开启内存淘汰功能(该参数的默认值为0即不设置内存上限),设置后当内存超过设定值就会开始执行淘汰机制。
通过制定maxmemory-policy noeviction选项认为配置淘汰策略,淘汰策略主要有如下几种:
- voltile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰
- allkeys-lru:从主数据集中挑选最近最少使用的数据淘汰
- allkeys-random:从主数据集中任意选择数据淘汰
- no-enviction:达到阈值后所有再申请内存的指令都不被允许
注:假设我们有一批键存储在Redis中,则有那么一个哈希表用于存储这批键及其值,如果这批键中有一部分设置了过期时间,那么这批键还会被存储到另外一个哈希表中,这个哈希表中的值对应的是键被设置的过期时间。设置了过期时间的数据集为主主数据集的子集。
各策略使用场景
-
如果我们的应用对缓存的访问符合幂律分布(也就是存在相对热点数据),或者外贸部太清楚我们应用的缓存访问分布状况,我们可以使用allkeys-lru策略。
-
如果我们的应用对于缓存key的访问概率相等,则可以使用allkeys-random这个策略。
-
volatile-lru策略和volatile-random策略适合我们讲一个Redis实例既应用于缓存和又应用于持久性存储的时候,然而我们也可以通过使用两个Redis实例来达到相同的效果,值得一提的是将key设置过期时间实际上会消耗更多的内存,因此我们建议使用allkeys-lru策略从而更有效率的使用内存。
Redis LRU近似算法
Redis 使用的是一种近似 LRU 算法:
-
key增加最近访问时间戳字段
-
选取一定数量的key(默认5,server.maxmemory_samples进行配置),比较最近访问时间。按照LRU算法淘汰key。
当 Redis 执行写操作时,发现内存超出 maxmemory,就会执行一次 LRU 淘汰算法。
注意:maxmemory_samples的值越大,Redis的近似LRU算法就越接近于严格LRU算法(队列结构重排,批量非热点数据缓存垃圾),但是相应消耗也变高,对性能有一定影响,样本值默认为5。
总结一下:
程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能。
-
对程序员的透明性:分页透明,但是分段需要程序员显示划分各个段。
-
地址空间的维度:分页的地址空间是一维的,即单一的线性地址空间,分段是二维的,在标识一个地址时,即需给出段名,又需给出段内地址。
-
大小是否可以改变:页的大小不可以改变,由系统把逻辑地址划分为页号和页内地址两部分;段的大小可以动态改变,决定于用户所编写的程序。
-
出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间,单位,分页是为了实现离散分配方式,以消减内存的外零头;分段主要是为了使得程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。