- Generator
- 클래스를 상속했을 때 메서드 실행 방식
- GIL 과 그로인한 성능 문제
- GC 작동 방식
- Celery
- PyPy 가 CPython 보다 빠른 이유
- 메모리 누수가 발생할 수 있는 경우
- Duck Typing
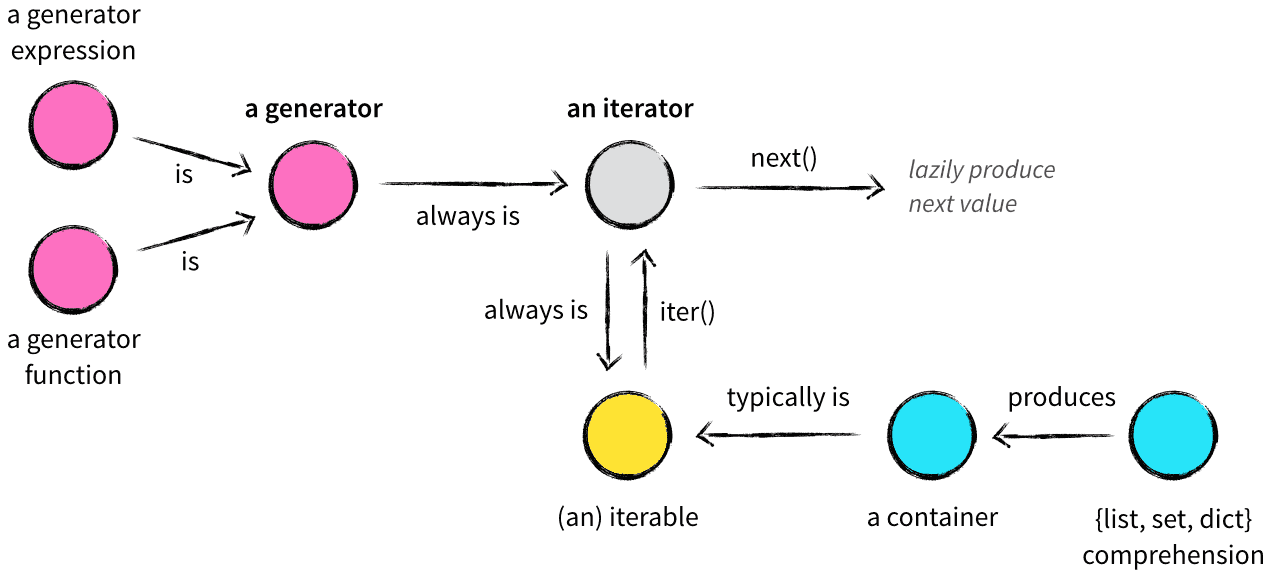
Generator(제네레이터)는 제네레이터 함수가 호출될 때 반환되는 iterator(이터레이터)의 일종이다. 제네레이터 함수는 일반적인 함수와 비슷하게 생겼지만 yield 구문을 사용해 데이터를 원하는 시점에 반환하고 처리를 다시 시작할 수 있다. 일반적인 함수는 진입점이 하나라면 제네레이터는 진입점이 여러개라고 생각할 수 있다. 이러한 특성때문에 제네레이터를 사용하면 원하는 시점에 원하는 데이터를 받을 수 있게된다.
>>> def generator():
... yield 1
... yield 'string'
... yield True
>>> gen = generator()
>>> gen
<generator object generator at 0x10a47c678>
>>> next(gen)
1
>>> next(gen)
'string'
>>> next(gen)
True
>>> next(gen)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration- yield 문이 포함된 제네레이터 함수를 실행하면 제네레이터 객체가 반환되는데 이 때는 함수의 내용이 실행되지 않는다.
next()라는 빌트인 메서드를 통해 제네레이터를 실행시킬 수 있으며next()메서드 내부적으로 iterator 를 인자로 받아 이터레이터의__next__()메서드를 실행시킨다.- 처음
__next__()메서드를 호출하면 함수의 내용을 실행하다 yield 문을 만났을 때 처리를 중단한다. - 이 때 모든 local state 는 유지되는데 변수의 상태, 명령어 포인터, 내부 스택, 예외 처리 상태를 포함한다.
- 그 후 제어권을 상위 컨텍스트로 양보(yield)하고 또
__next__()가 호출되면 제네레이터는 중단된 시점부터 다시 시작한다.
yield 문의 값은 어떤 메서드를 통해 제네레이터가 다시 동작했는지에 따라 다른데,
__next__()를 사용하면 None 이고send()를 사용하면 메서드로 전달 된 값을 갖게되어 외부에서 데이터를 입력받을 수 있게 된다.
List, Set, Dict 표현식은 iterable(이터러블)하기에 for 표현식 등에서 유용하게 쓰일 수 있다. 이터러블 객체는 유용한 한편 모든 값을 메모리에 담고 있어야 하기 때문에 큰 값을 다룰 때는 별로 좋지 않다. 제네레이터를 사용하면 yield 를 통해 그때그때 필요한 값만을 받아 쓰기때문에 모든 값을 메모리에 들고 있을 필요가 없게된다.
range()함수는 Python 2.x 에서 리스트를 반환하고 Python 3.x 에선 range 객체를 반환한다. 이 range 객체는 제네레이터, 이터레이터가 아니다. 실제로next(range(1))를 호출해보면TypeError: 'range' object is not an iterator오류가 발생한다. 그렇지만 내부 구현상 제네레이터를 사용한 것 처럼 메모리 사용에 있어 이점이 있다.
>>> import sys
>>> a = [i for i in range(100000)]
>>> sys.getsizeof(a)
824464
>>> b = (i for i in range(100000))
>>> sys.getsizeof(b)
88다만 제네레이터는 그때그때 필요한 값을 던져주고 기억하지는 않기 때문에 a 리스트가 여러번 사용될 수 있는 반면 b 제네레이터는 한번 사용된 후 소진된다. 이는 모든 이터레이터가 마찬가지인데 List, Set 은 이터러블하지만 이터레이터는 아니기에 소진되지 않는다.
>>> len(list(b))
100000
>>> len(list(b))
0또한 while True 구문으로 제공받을 데이터가 무한하거나, 모든 값을 한번에 계산하기엔 시간이 많이 소요되어 그때 그때 필요한 만큼만 받아 계산하고 싶을 때 제네레이터를 활용할 수 있다.
인스턴스의 메서드를 실행한다고 가정할 때 __getattribute__()로 bound 된 method 를 가져온 후 메서드를 실행한다. 메서드를 가져오는 순서는 __mro__에 따른다. MRO(method resolution order)는 메소드를 확인하는 순서로 파이썬 2.3 이후 C3 알고리즘이 도입되어 지금까지 사용되고있다. 단일상속 혹은 다중상속일 때 어떤 순서로 메서드에 접근할지는 해당 클래스의 __mro__에 저장되는데 왼쪽에 있을수록 우선순위가 높다. B, C 를 다중상속받은 D 클래스가 있고, B 와 C 는 각각 A 를 상속받았을 때(다이아몬드 상속) D 의 mro 를 조회하면 볼 수 있듯이 부모클래스는 반드시 자식클래스 이후에 위치해있다. 최상위 object 클래스까지 확인했는데도 적절한 메서드가 없으면 AttributeError를 발생시킨다.
class A:
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
>>> D.__mro__
(__main__.D, __main__.B, __main__.C, __main__.A, object)Python 2.3 이후 위 이미지와 같은 상속을 시도하려하면 TypeError: Cannot create a consistent method resolution 오류가 발생한다.
- INHERITANCE(상속), MRO
- What does mro do
- Python 2.3 이후의 MRO 알고리즘에 대한 파이썬 공식 문서
- What is a method in python
GIL 때문에 성능 문제가 대두되는 경우는 압축, 정렬, 인코딩 등 수행시간에 CPU 의 영향이 큰 작업(CPU bound)을 멀티 스레드로 수행하도록 한 경우다. 이 땐 GIL 때문에 멀티 스레드로 작업을 수행해도 싱글 스레드일 때와 별반 차이가 나지 않는다. 이를 해결하기 위해선 멀티 스레드는 파일, 네트워크 IO 같은 IO bound 프로그램에 사용하고 멀티 프로세스를 활용해야한다.
GIL 은 스레드에서 사용되는 Lock 을 인터프리터 레벨로 확장한 개념인데 여러 스레드가 동시에 실행되는걸 방지한다. 더 정확히 말하자면 어느 시점이든 하나의 Bytecode 만이 실행되도록 강제한다. 각 스레드는 다른 스레드에 의해 GIL 이 해제되길 기다린 후에야 실행될 수 있다. 즉 멀티 스레드로 만들었어도 본질적으로 싱글 스레드로 동작한다.

코어 개수는 점점 늘어만 가는데 이 GIL 때문에 그 장점을 제대로 살리지 못하기만 하는 것 같으나 이 GIL 로 인한 장점도 존재한다. GIL 을 활용한 멀티 스레드가 그렇지 않은 멀티 스레드보다 구현이 쉬우며, 레퍼런스 카운팅을 사용하는 메모리 관리 방식에서 GIL 덕분에 오버헤드가 적어 싱글 스레드일 때 fine grained lock 방식보다 성능이 우월하다. 또한 C extension 을 활용할 때 GIL 은 해제되므로 C library 를 사용하는 CPU bound 프로그램을 멀티 스레드로 실행하는 경우 더 빠를 수 있다.
파이썬에선 기본적으로 garbage collection(가비지 컬렉션)과 reference counting(레퍼런스 카운팅)을 통해 할당 된 메모리를 관리한다. 기본적으로 참조 횟수가 0 이된 객체를 메모리에서 해제하는 레퍼런스 카운팅 방식을 사용하지만, 참조 횟수가 0 은 아니지만 도달할 수 없는 상태인 reference cycles(순환 참조)가 발생했을 때는 가비지 컬렉션으로 그 상황을 해결한다.
엄밀히 말하면 레퍼런스 카운팅 방식을 통해 객체를 메모리에서 해제하는 행위가 가비지 컬렉션의 한 형태지만 여기서는 순환 참조가 발생했을 때 cyclic garbage collector 를 통한 가비지 컬렉션과 레퍼런스 카운팅을 통한 가비지 컬렉션을 구분했다.
여기서 '순환 참조가 발생한건 어떻게 탐지하지?', '주기적으로 감시한다면 그 주기의 기준은 뭘까?', '가비지 컬렉션은 언제 발생하지?' 같은 의문이 들 수 있는데 이 의문을 해결하기 전에 잠시 레퍼런스 카운팅, 순환 참조, 파이썬의 가비지 컬렉터에 대한 간단한 개념을 짚고 넘어가자. 이 개념을 알고 있다면 바로 가비지 컬렉션의 작동 방식 단락을 읽으면 된다.
모든 객체는 참조당할 때 레퍼런스 카운터를 증가시키고 참조가 없어질 때 카운터를 감소시킨다. 이 카운터가 0 이 되면 객체가 메모리에서 해제한다. 어떤 객체의 레퍼런스 카운트를 보고싶다면 sys.getrefcount()로 확인할 수 있다.
Py_INCREF()와 Py_DECREF()를 통한 카운터 증감
카운터를 증감시키는 명령은 아래와 같이 object.h에 선언되어있는데 카운터를 증가시킬 때는 단순히 ob_refcnt를 1 증가시키고 감소시킬때는 1 감소시킴과 동시에 카운터가 0 이되면 메모리에서 객체를 해제하는 것을 확인할 수 있다.
#define Py_INCREF(op) ( \
_Py_INC_REFTOTAL _Py_REF_DEBUG_COMMA \
((PyObject *)(op))->ob_refcnt++)
#define Py_DECREF(op) \
do { \
PyObject *_py_decref_tmp = (PyObject *)(op); \
if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA \
--(_py_decref_tmp)->ob_refcnt != 0) \
_Py_CHECK_REFCNT(_py_decref_tmp) \
else \
_Py_Dealloc(_py_decref_tmp); \
} while (0)더 정확한 정보는 파이썬 공식 문서를 참고하면 자세하게 설명되어있다.
순환 참조의 간단한 예제는 자기 자신을 참조하는 객체다.
>>> l = []
>>> l.append(l)
>>> del ll의 참조 횟수는 1 이지만 이 객체는 더이상 접근할 수 없으며 레퍼런스 카운팅 방식으로는 메모리에서 해제될 수 없다.
또 다른 예로는 서로를 참조하는 객체다.
>>> a = Foo() # 0x60
>>> b = Foo() # 0xa8
>>> a.x = b # 0x60의 x는 0xa8를 가리킨다.
>>> b.x = a # 0xa8의 x는 0x60를 가리킨다.
# 이 시점에서 0x60의 레퍼런스 카운터는 a와 b.x로 2
# 0xa8의 레퍼런스 카운터는 b와 a.x로 2다.
>>> del a # 0x60은 1로 감소한다. 0xa8은 b와 0x60.x로 2다.
>>> del b # 0xa8도 1로 감소한다.이 상태에서 0x60.x와 0xa8.x가 서로를 참조하고 있기 때문에 레퍼런스 카운트는 둘 다 1 이지만 도달할 수 없는 가비지가 된다.
파이썬의 gc 모듈을 통해 가비지 컬렉터를 직접 제어할 수 있다. gc 모듈은 cyclic garbage collection 을 지원하는데 이를 통해 reference cycles(순환 참조)를 해결할 수 있다. gc 모듈은 오로지 순환 참조를 탐지하고 해결하기위해 존재한다. gc 파이썬 공식문서에서도 순환 참조를 만들지 않는다고 확신할 수 있으면 gc.disable()을 통해 garbage collector 를 비활성화 시켜도 된다고 언급하고 있다.
Since the collector supplements the reference counting already used in Python, you can disable the collector if you are sure your program does not create reference cycles.
순환 참조 상태도 해결할 수 있는 cyclic garbage collection 이 어떤 방식으로 동작하는지는 결국 어떤 기준으로 가비지 컬렉션이 발생하고 어떻게 순환 참조를 감지하는지에 관한 내용이다. 이에 대해 차근차근 알아보자.
앞에서 제기했던 의문은 결국 발생 기준에 관한 의문이다. 가비지 컬렉터는 내부적으로 generation(세대)과 threshold(임계값)로 가비지 컬렉션 주기와 객체를 관리한다. 세대는 0 세대, 1 세대, 2 세대로 구분되는데 최근에 생성된 객체는 0 세대(young)에 들어가고 오래된 객체일수록 2 세대(old)에 존재한다. 더불어 한 객체는 단 하나의 세대에만 속한다. 가비지 컬렉터는 0 세대일수록 더 자주 가비지 컬렉션을 하도록 설계되었는데 이는 generational hypothesis에 근거한다.
generational hypothesis의 두 가지 가설
- 대부분의 객체는 금방 도달할 수 없는 상태(unreachable)가 된다.
- 오래된 객체(old)에서 젊은 객체(young)로의 참조는 아주 적게 존재한다.

주기는 threshold 와 관련있는데 gc.get_threshold()로 확인해 볼 수 있다.
>>> gc.get_threshold()
(700, 10, 10)각각 threshold 0, threshold 1, threshold 2을 의미하는데 n 세대에 객체를 할당한 횟수가 threshold n을 초과하면 가비지 컬렉션이 수행되며 이 값은 변경될 수 있다.
0 세대의 경우 메모리에 객체가 할당된 횟수에서 해제된 횟수를 뺀 값, 즉 객체 수가 threshold 0을 초과하면 실행된다. 다만 그 이후 세대부터는 조금 다른데 0 세대 가비지 컬렉션이 일어난 후 0 세대 객체를 1 세대로 이동시킨 후 카운터를 1 증가시킨다. 이 1 세대 카운터가 threshold 1을 초과하면 그 때 1 세대 가비지 컬렉션이 일어난다. 러프하게 말하자면 0 세대 가비지 컬렉션이 객체 생성 700 번만에 일어난다면 1 세대는 7000 번만에, 2 세대는 7 만번만에 일어난다는 뜻이다.
이를 말로 풀어서 설명하려니 조금 복잡해졌지만 간단하게 말하면 메모리 할당시 generation[0].count++, 해제시 generation[0].count--가 발생하고, generation[0].count > threshold[0]이면 genreation[0].count = 0, generation[1].count++이 발생하고 generation[1].count > 10일 때 0 세대, 1 세대 count 를 0 으로 만들고 generation[2].count++을 한다는 뜻이다.
이렇듯 가비지 컬렉터는 세대와 임계값을 통해 가비지 컬렉션의 주기를 관리한다. 이제 가비지 컬렉터가 어떻게 순환 참조를 발견하는지 알아보기에 앞서 가비지 컬렉션의 실행 과정(라이프 사이클)을 간단하게 알아보자.
새로운 객체가 만들어 질 때 파이썬은 객체를 메모리와 0 세대에 할당한다. 만약 0 세대의 객체 수가 threshold 0보다 크면 collect_generations()를 실행한다.
코드와 함께하는 더 자세한 설명
새로운 객체가 만들어 질 때 파이썬은 _PyObject_GC_Alloc()을 호출한다. 이 메서드는 객체를 메모리에 할당하고, 가비지 컬렉터의 0 세대의 카운터를 증가시킨다. 그 다음 0 세대의 객체 수가 threshold 0보다 큰지, gc.enabled가 true 인지, threshold 0이 0 이 아닌지, 가비지 컬렉션 중이 아닌지 확인하고, 모든 조건을 만족하면 collect_generations()를 실행한다.
다음은 _PyObject_GC_Alloc()을 간략화 한 소스며 메서드 전체 내용은 여기에서 확인할 수 있다.
_PyObject_GC_Alloc() {
// ...
gc.generations[0].count++; /* 0세대 카운터 증가 */
if (gc.generations[0].count > gc.generations[0].threshold && /* 임계값을 초과하며 */
gc.enabled && /* 사용가능하며 */
gc.generations[0].threshold && /* 임계값이 0이 아니고 */
!gc.collecting) /* 컬렉션 중이 아니면 */
{
gc.collecting = 1;
collect_generations();
gc.collecting = 0;
}
// ...
}참고로 gc를 끄고싶으면 gc.disable()보단 gc.set_threshold(0)이 더 확실하다. disable()의 경우 서드 파티 라이브러리에서 enable()하는 경우가 있다고 한다.
collect_generations()이 호출되면 모든 세대(기본적으로 3 개의 세대)를 검사하는데 가장 오래된 세대(2 세대)부터 역으로 확인한다. 해당 세대에 객체가 할당된 횟수가 각 세대에 대응되는 threshold n보다 크면 collect()를 호출해 가비지 컬렉션을 수행한다.
코드
collect()가 호출될 때 해당 세대보다 어린 세대들은 모두 통합되어 가비지 컬렉션이 수행되기 때문에 break를 통해 검사를 중단한다.
다음은 collect_generations()을 간략화 한 소스며 메서드 전체 내용은 여기에서 확인할 수 있다.
static Py_ssize_t
collect_generations(void)
{
int i;
for (i = NUM_GENERATIONS-1; i >= 0; i--) {
if (gc.generations[i].count > gc.generations[i].threshold) {
collect_with_callback(i);
break;
}
}
}
static Py_ssize_t
collect_with_callback(int generation)
{
// ...
result = collect(generation, &collected, &uncollectable, 0);
// ...
}collect() 메서드는 순환 참조 탐지 알고리즘을 수행하고 특정 세대에서 도달할 수 있는 객체(reachable)와 도달할 수 없는 객체(unreachable)를 구분하고 도달할 수 없는 객체 집합을 찾는다. 도달할 수 있는 객체 집합은 다음 상위 세대로 합쳐지고(0 세대에서 수행되었으면 1 세대로 이동), 도달할 수 없는 객체 집합은 콜백을 수행 한 후 메모리에서 해제된다.
이제 정말 순환 참조 탐지 알고리즘을 알아볼 때가 됐다.
먼저 순환 참조는 컨테이너 객체(e.g. tuple, list, set, dict, class)에 의해서만 발생할 수 있음을 알아야한다. 컨테이너 객체는 다른 객체에 대한 참조를 보유할 수 있다. 그러므로 정수, 문자열은 무시한채 관심사를 컨테이너 객체에만 집중할 수 있다.
순환 참조를 해결하기 위한 아이디어로 모든 컨테이너 객체를 추적한다. 여러 방법이 있겠지만 객체 내부의 링크 필드에 더블 링크드 리스트를 사용하는 방법이 가장 좋다. 이렇게 하면 추가적인 메모리 할당 없이도 컨테이너 객체 집합에서 객체를 빠르게 추가하고 제거할 수 있다. 컨테이너 객체가 생성될 때 이 집합에 추가되고 제거될 때 집합에서 삭제된다.
PyGC_Head에 선언된 더블 링크드 리스트
더블 링크드 리스트는 다음과 같이 선언되어 있으며 objimpl.h 코드에서 확인해볼 수 있다.
#ifndef Py_LIMITED_API
typedef union _gc_head {
struct {
union _gc_head *gc_next;
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
double dummy; /* force worst-case alignment */
} PyGC_Head;이제 모든 컨테이터 객체에 접근할 수 있으니 순환 참조를 찾을 수 있어야 한다. 순환 참조를 찾는 과정은 다음과 같다.
- 객체에
gc_refs필드를 레퍼런스 카운트와 같게 설정한다. - 각 객체에서 참조하고 있는 다른 컨테이너 객체를 찾고, 참조되는 컨테이너의
gc_refs를 감소시킨다. gc_refs가 0 이면 그 객체는 컨테이너 집합 내부에서 자기들끼리 참조하고 있다는 뜻이다.- 그 객체를 unreachable 하다고 표시한 뒤 메모리에서 해제한다.
이제 우리는 가비지 콜렉터가 어떻게 순환 참조 객체를 탐지하고 메모리에서 해제하는지 알았다.
아래 예제는 보기 쉽게 가공한 예제이며 실제
collect()의 동작과는 차이가 있다. 정확한 작동 방식은 아래에서 다시 서술한다. 혹은collect()코드를 참고하자.
아래의 예제를 통해 가비지 컬렉터가 어떤 방법으로 순환 참조 객체인 Foo(0)과 Foo(1)을 해제하는지 알아보겠다.
a = [1]
# Set: a:[1]
b = ['a']
# Set: a:[1] <-> b:['a']
c = [a, b]
# Set: a:[1] <-> b:['a'] <-> c:[a, b]
d = c
# Set: a:[1] <-> b:['a'] <-> c,d:[a, b]
# 컨테이너 객체가 생성되지 않았기에 레퍼런스 카운트만 늘어난다.
e = Foo(0)
# Set: a:[1] <-> b:['a'] <-> c,d:[a, b] <-> e:Foo(0)
f = Foo(1)
# Set: a:[1] <-> b:['a'] <-> c,d:[a, b] <-> e:Foo(0) <-> f:Foo(1)
e.x = f
# Set: a:[1] <-> b:['a'] <-> c,d:[a, b] <-> e:Foo(0) <-> f,Foo(0).x:Foo(1)
f.x = e
# Set: a:[1] <-> b:['a'] <-> c,d:[a, b] <-> e,Foo(1).x:Foo(0) <-> f,Foo(0).x:Foo(1)
del e
# Set: a:[1] <-> b:['a'] <-> c,d:[a, b] <-> Foo(1).x:Foo(0) <-> f,Foo(0).x:Foo(1)
del f
# Set: a:[1] <-> b:['a'] <-> c,d:[a, b] <-> Foo(1).x:Foo(0) <-> Foo(0).x:Foo(1)위 상황에서 각 컨테이너 객체의 레퍼런스 카운트는 다음과 같다.
# ref count
[1] <- a,c = 2
['a'] <- b,c = 2
[a, b] <- c,d = 2
Foo(0) <- Foo(1).x = 1
Foo(1) <- Foo(0).x = 11 번 과정에서 각 컨테이너 객체의 gc_refs가 설정된다.
# gc_refs
[1] = 2
['a'] = 2
[a, b] = 2
Foo(0) = 1
Foo(1) = 12 번 과정에서 컨테이너 집합을 순회하며 gc_refs을 감소시킨다.
[1] = 1 # [a, b]에 의해 참조당하므로 1 감소
['a'] = 1 # [a, b]에 의해 참조당하므로 1 감소
[a, b] = 2 # 참조당하지 않으므로 그대로
Foo(0) = 0 # Foo(1)에 의해 참조당하므로 1 감소
Foo(1) = 0 # Foo(0)에 의해 참조당하므로 1 감소3 번 과정을 통해 gc_refs가 0 인 순환 참조 객체를 발견했다. 이제 이 객체를 unreachable 집합에 옮겨주자.
unreachable | reachable
| [1] = 1
Foo(0) = 0 | ['a'] = 1
Foo(1) = 0 | [a, b] = 2이제 Foo(0)와 Foo(1)을 메모리에서 해제하면 가비지 컬렉션 과정이 끝난다.
collect() 메서드는 현재 세대와 어린 세대를 합쳐 순환 참조를 검사한다. 이 합쳐진 세대를 young으로 이름 붙이고 다음의 과정을 거치며 최종적으로 도달 할 수 없는 객체가 모인 unreachable 리스트를 메모리에서 해제하고 young 에 남아있는 객체를 다음 세대에 할당한다.
update_refs(young)
subtract_refs(young)
gc_init_list(&unreachable)
move_unreachable(young, &unreachable)update_refs()는 모든 객체의 레퍼런스 카운트 사본을 만든다. 이는 가비지 컬렉터가 실제 레퍼런스 카운트를 건드리지 않게 하기 위함이다.
subtract_refs()는 각 객체 i 에 대해 i 에 의해 참조되는 객체 j 의 gc_refs를 감소시킨다. 이 과정이 끝나면 (young 세대에 남아있는 객체의 레퍼런스 카운트) - (남아있는 gc_refs) 값이 old 세대에서 young 세대를 참조하는 수와 같다.
move_unreachable() 메서드는 young 세대를 스캔하며 gc_refs가 0 인 객체를 unreachable 리스트로 이동시키고 GC_TENTATIVELY_UNREACHABLE로 설정한다. 왜 완전히 unreachable이 아닌 임시로(Tentatively) 설정하냐면 나중에 스캔될 객체로부터 도달할 수도 있기 때문이다.
예제 보기
a, b = Foo(0), Foo(1)
a.x = b
b.x = a
c = b
del a
del b
# 위 상황을 요약하면 다음과 같다.
Foo(0).x = Foo(1)
Foo(1).x = Foo(0)
c = Foo(1)이 때 상황은 다음과 같은데 Foo(0)의 gc_refs가 0 이어도 뒤에 나올 Foo(1)을 통해 도달 할 수 있다.
| young | ref count | gc_refs | reachable |
|---|---|---|---|
Foo(0) |
1 | 0 | c.x |
Foo(1) |
2 | 1 | c |
0 이 아닌 객체는 GC_REACHABLE로 설정하고 그 객체가 참조하고 있는 객체 또한 찾아가(traverse) GC_REACHABLE로 설정한다. 만약 그 객체가 unreachable 리스트에 있던 객체라면 young 리스트의 끝으로 보낸다. 굳이 young의 끝으로 보내는 이유는 그 객체 또한 다른 gc_refs가 0 인 객체를 참조하고 있을 수 있기 때문이다.
예제 보기
a, b = Foo(0), Foo(1)
a.x = b
b.x = a
c = b
d = Foo(2)
d.x = d
a.y = d
del d
del a
del b
# 위 상황을 요약하면 다음과 같다.
Foo(0).x = Foo(1)
Foo(1).x = Foo(0)
c = Foo(1)
Foo(0).y = Foo(2)| young | ref count | gc_refs | reachable |
|---|---|---|---|
Foo(0) |
1 | 0 | c.x |
Foo(1) |
2 | 1 | c |
Foo(2) |
1 | 0 | c.x.y |
이 상황에서 Foo(0)은 unreachable 리스트에 있다가 Foo(1)을 조사하며 다시 young 리스트의 맨 뒤로 돌아왔고, Foo(2)도 unreachable 리스트에 갔지만 곧 Foo(0)에 의해 참조될 수 있음을 알고 다시 young 리스트로 돌아온다.
young 리스트의 전체 스캔이 끝나면 이제 unreachable 리스트에 있는 객체는 정말 도달할 수 없다. 이제 이 객체들을 메모리에서 해제되고 young 리스트의 객체들은 상위 세대로 합쳐진다.
- Instagram 이 gc 를 없앤 이유
- 파이썬 Garbage Collection
- Finding reference cycle
- Naver D2 - Java Garbage Collection
- gc 의 threshold
- Garbage Collection for Python
- How does garbage collection in Python work
- gcmodule.c
Celery는 메시지 패싱 방식의 분산 비동기 작업 큐다. 작업(Task)은 브로커(Broker)를 통해 메시지(Message)로 워커(Worker)에 전달되어 처리된다. 작업은 멀티프로세싱, eventlet, gevent 를 사용해 하나 혹은 그 이상의 워커에서 동시적으로 실행되며 백그라운드에서 비동기적으로 실행될 수 있다.
간단히 말하면 CPython 은 일반적인 인터프리터인데 반해 PyPy 는 실행 추적 JIT(Just In Time) 컴파일을 제공하는 인터프리터기 때문이다. PyPy 는 RPython 으로 컴파일된 인터프리터인데, C 로 작성된 RPython 툴체인으로 인터프리터 소스에 JIT 컴파일을 위한 힌트를 추가해 CPython 보다 빠른 실행 속도를 가질 수 있게 되었다.
PyPy 는 파이썬으로 만들어진 파이썬 인터프리터다. 일반적으로 파이썬 인터프리터를 다시 한번 파이썬으로 구현한 것이기에 속도가 매우 느릴거라 생각하지만 실제 PyPy 는 스피드 센터에서 볼 수 있듯 CPython 보다 빠르다.
메소드 단위로 최적화 하는 전통적인 JIT 과 다르게 런타임에서 자주 실행되는 루프를 최적화한다.
RPython은 이런 실행 추적 JIT 컴파일을 C 로 구현해 툴체인을 포함한다. 그래서 RPython 으로 인터프리터를 작성하고 툴체인으로 힌트를 추가하면 인터프리터에 실행추적 JIT 컴파일러를 빌드한다. 참고로 RPython 은 PyPy 프로젝트 팀이 만든 일종의 인터프리터 제작 프레임워크(언어)다. 동적 언어인 Python 에서 표준 라이브러리와 문법에 제약을 가해 변수의 정적 컴파일이 가능하도록 RPython 을 만들었으며, 동적 언어 인터프리터를 구현하는데 사용된다.
이렇게 언어 사양(파이썬 언어 규칙, BF 언어 규칙 등)과 구현(실제 인터프리터 제작)을 분리함으로써 어떤 동적 언어에 대해서라도 자동으로 JIT(Just-in-Time) 컴파일러를 생성할 수 있게 되었다.
- RPython 공식 레퍼런스
- PyPy - wikipedia
- PyPy 가 CPython 보다 빠를 수 있는 이유 - memorable
- PyPy 와 함께 인터프리터 작성하기
- 알파희 - PyPy/RPython 으로 20 배 빨라지는 아희 JIT 인터프리터
- PyPy 가 CPython 보다 빠를 수 있는 이유 - 홍민희
메모리 누수를 어떻게 정의하냐에 따라 조금 다르다.
a = 1을 선언한 후에 프로그램에서 더 이상a를 사용하지 않아도 이것을 메모리 누수라고 볼 수 있다. 다만 여기서는 사용자의 부주의로 인해 발생하는 메모리 누수만 언급한다.
대표적으로 mutable 객체를 기본 인자값으로 사용하는 경우에 메모리 누수가 일어난다.
def foo(a=[]):
a.append(time.time())
return a위의 경우 foo()를 호출할 때마다 기본 인자값인 a에 타임스탬프 값이 추가된다. 이는 의도하지 않은 결과를 초래하므로 보통의 경우 a=None으로 두고 함수 내부에서 if a is None 구문으로 빈 리스트를 할당해준다.
다른 경우로 웹 애플리케이션에서 timeout 이 없는 캐시 데이터를 생각해 볼 수 있다. 요청이 들어올수록 캐시 데이터는 쌓여만 가는데 이를 해제할 루틴을 따로 만들어두지 않는다면 이도 메모리 누수를 초래한다.
클래스 내 __del__ 메서드를 재정의하는 행위도 메모리 누수를 일으킬 수 있다. 순환 참조 중인 클래스가 __del__ 메서드를 재정의하고 있다면 가비지 컬렉터로 해제되지 않는다.
Duck typing이란 특히 동적 타입을 가지는 프로그래밍 언어에서 많이 사용되는 개념으로, 객체의 실제 타입보다는 객체의 변수와 메소드가 그 객체의 적합성을 결정하는 것을 의미한다. Duck typing이라는 용어는 흔히 duck test라고 불리는 한 구절에서 유래됐다.
If it walks like a duck and it quacks like a duck, then it must be a duck.
만일 그 새가 오리처럼 걷고, 오리처럼 꽥꽥거린다면 그 새는 오리일 것이다.
동적 타입 언어인 파이썬은 메소드 호출이나 변수 접근시 타입 검사를 하지 않으므로 duck typing을 넒은 범위에서 활용할 수 있다. 다음은 간단한 duck typing의 예시다.
class Duck:
def walk(self):
print('뒤뚱뒤뚱')
def quack(self):
print('Quack!')
class Mallard: # 청둥오리
def walk(self):
print('뒤뚱뒤뒤뚱뒤뚱')
def quack(self):
print('Quaaack!')
class Dog:
def run(self):
print('타다다다')
def bark(self):
print('왈왈')
def walk_and_quack(animal):
animal.walk()
animal.quack()
walk_and_quack(Duck()) # prints '뒤뚱뒤뚱', prints 'Quack!'
walk_and_quack(Mallard()) # prints '뒤뚱뒤뒤뚱뒤뚱', prints 'Quaaack!'
walk_and_quack(Dog()) # AttributeError : 'Dog' object has no attribute 'walk'위 예시에서 Duck 과 Mallard 는 둘 다 walk() 와 quack() 을 구현하고 있기 때문에 walk_and_quack() 이라는 함수의 인자로서 적합하다.
그러나 Dog 는 두 메소드 모두 구현되어 있지 않으므로 해당 함수의 인자로서 부적합하다. 즉, Dog 는 적절한 duck typing에 실패한 것이다.
Python에서는 다양한 곳에서 duck typing을 활용한다. __len__()을 구현하여 길이가 있는 무언가 를 표현한다던지 (흔히 listy하다고 표현한다), 또는 __iter__() 와 __getitem__() 을 구현하여 iterable을 duck-typing한다.
굳이 Iterable (가명) 이라는 interface를 상속받지 않고 __iter__()와 __getitem__()을 구현하기만 하면 for ... in 에서 바로 사용할 수 있다.
이와 같은 방식은 일반적으로 interface를 구현하거나 클래스를 상속하는 방식으로
인자나 변수의 적합성을 runtime 이전에 판단하는 정적 타입 언어들과 비교된다.
자바나 스칼라에서는 interface, c++는 template 을 활용하여 타입의 적합성을 보장한다.
(c++의 경우 template으로 duck typing과 같은 효과를 낼 수 있다 참고)
- Templates and Duck Typing
- Strong and Weak Typing
- Python Duck Typing - or, what is an interface?
- Quora : What is duck typing in python?
- Duck Test
Python.end