
Link to the published paper: https://www.mdpi.com/1424-8220/21/10/3465/htm
- OS Windows 10
- FLIR Atlas SDK for MATLAB
- Documentation of the SDK can be found here.
- MATLAB 2019.x
- Computer Vision Toolbox
- ROS Toolbox
- Ubuntu 16.04
- Python 3.x.x
- OpenCV 4.x.x.
- NumPy: pip install numpy
- Pandas: pip install pandas
- SciPy: pip install scipy
- imutils: pip install imutils
- face_recognition: pip install face_recognition
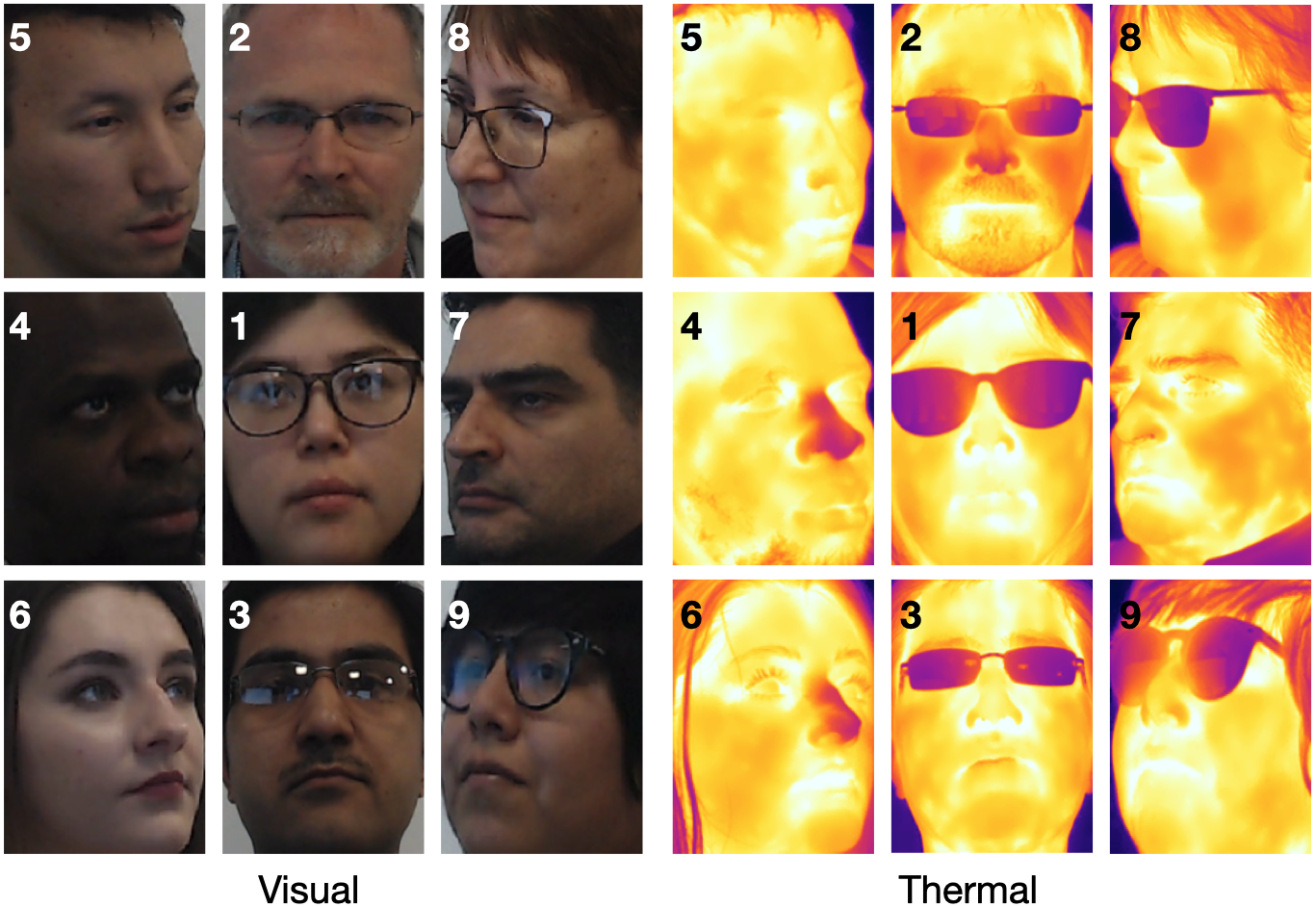
FLIR T540 thermal camera (464×348 pixels, 24◦ FOV) and a Logitech C920 Pro HD web-camera (768×512 pixels, 78◦ FOV) with a built-in dual stereo microphone were used for data collection purpose. Each subject participated in two trials where each trial consisted of two sessions. In the first session, subjects were silent and still, with the operator capturing the visual and thermal video streams through the procession of nine collection angles. The second session consisted of the subject reading a series of commands as presented one-by-one on the video screens, as the visual, thermal and audio data was collected from the same nine camera positions.
- Launch the MATLAB and start the global ROS node via MATLAB's terminal: rosinit
- Open /record_matlab/record_only_video.m and initialize the following parameters:
- sub_id: a subject ID.
- trial_id: a trial ID.
- numOfPosit: a total number of positions.
- numOfFrames: a total number of frames per position.
- pauseBtwPos: a pause (sec) that is necessary for moving cameras from one position to another.
- path: a path to save the recorded video files.
- Launch /record_matlab/record_only_video.m
- Launch the MATLAB and start the global ROS node via MATLAB's terminal: rosinit
- Open /record_matlab/record_audio_video.m and initialize the following parameters:
- sub_id: a subject ID.
- trial_id: a trial ID.
- numOfPosit: a total number of positions.
- fpc: a number of frames necessary for reading one character.
- pauseBtwPos: a pause (sec) that is necessary for moving cameras from one position to another.
- path: a path to save the recorded audio and video files.
- Launch /record_matlab/record_audio_video.m
- To extract frames from the recorded visual and thermal video streams:
- Open record_matlab/extract_images_from_videos.m file.
- Initialize the following parameters: sub_id - a subject ID, trial_id - a trial ID, path_vid - a path to the recorded video files, path_rgb - a path to save the extracted visual frames, path_thr - a path to save the extracted thermal frames.
- Launch record_matlab/extract_images_from_videos.m
- To align the extracted visual frames with their thermal pairs, run align_session_one.py script with the following arguments:
- dataset: a path to the SpeakingFaces dataset.
- sub_info: subjectID, trialID, positionID.
- dy: a list of shifts (pixels) between streams in y-axis.
- dx: a list of shifts (pixels) between streams in x-axis.
- show: visualize (1) or not (0) a preliminary result of the alignment.

- Alignment for all subjects can be done using align_session_one_all.py script and metadata stored in metadata/session_1/ directory.
- To split audio and video files based on commands:
- Open record_matlab/extract_video_audio_by_commands.m file.
- Initialize the following parameters: sub_id - a subject ID, trial_id - a trial ID, path_vid - a path to the recorded video files, path_rgb - a path to save the extracted visual videos, path_thr - a path to save the extracted thermal videos by commands, path_mic1 - a path to save the extracted audio files by commands from the microphone #1, path_mic2 - a path to save the extracted audio files by commands from the microphone #2.
- Launch record_matlab/extract_video_audio_by_commands.m
- Note, the recordings from the two microphones are identical. The extracted audio files from the first microphone were manually trimmed and validated. Based on this processed data, the extracted recordings from the second microphone were automatically trimmed using trim_audio.py script.
- To extract frames from visual and thermal video files based on the trimmed audio files, run extract_images_by_commands.py script. It estimates a length of the trimmed audio file and extracts a necessary number of frames accordingly.
- To align the extracted frames, and also to crop the mouth region of interest (ROI), run align_crop_session_two.py script with the following arguments:
- dataset: a path to the SpeakingFaces dataset.
- sub_info: subjectID, trialID, positionID.
- dy: a list of shifts (pixels) between streams in y-axis.
- dx: a list of shifts (pixels) between streams in x-axis.
- model: a face detection model.
- show: visualize (1) or not (0) a preliminary result of the alignment.
If the face detection is selected, then the ROI is cropped automatically using facial landmarks:

Otherwise the ROI is defined manually:

- Alignment for all subjects can be done using align_session_two_all.py scripts based on the metadata stored in metadata/session_2/ directory.

@Article{s21103465,
AUTHOR = {Abdrakhmanova, Madina and Kuzdeuov, Askat and Jarju, Sheikh and Khassanov, Yerbolat and Lewis, Michael and Varol, Huseyin Atakan},
TITLE = {SpeakingFaces: A Large-Scale Multimodal Dataset of Voice Commands with Visual and Thermal Video Streams},
JOURNAL = {Sensors},
VOLUME = {21},
YEAR = {2021},
NUMBER = {10},
ARTICLE-NUMBER = {3465},
URL = {https://www.mdpi.com/1424-8220/21/10/3465},
ISSN = {1424-8220},
DOI = {10.3390/s21103465}
}