CAP理论是分布式场景绕不开的重要理论
- 一致性:所有节点在同一时间具有一样的数据;
- 可用性:保证每个请求不管成功还是失败都有响应;
- 分区容忍性:系统中任意信息的丢失和失败不会影响系统的继续运作;
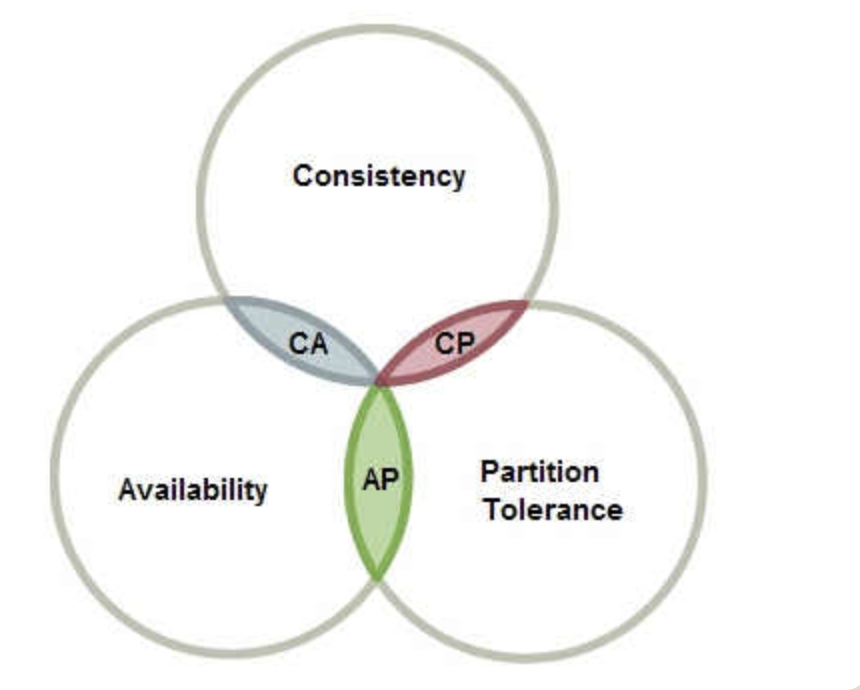
关于分区容忍性P的理解,大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition),分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。
关于提高分区容忍性的办法,就是把同一份数据复制到多个节点上,分布到各个区里,容忍度就提高了。一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。
剩下CAP的C和A无法同时做到,原因是 如果C是第一需求的话,那么会影响A的性能,因为要数据同步,不然请求结果就会有差异,但数据同步会消耗时间,期间可用性就会降低。
如果A是第一需求的话,那么只要有一个服务在,就能正常接受请求,但是对于返回结果变化不能保证一致性,原因是在分布式部署的时候,不能保障每个环境下处理速度。
| Nacos | Eureka | Consul | Zookeeper | |
|---|---|---|---|---|
| CAP理论 | CP+AP | AP | CP | CP |
与Eureka有所不同,Apache Zookeeper在设计时就遵循CP原则,即任何时候对Zookeeper访问请求能得到一致的数据结果,同时系统对网络分区具备容错性,但是Zookeeper不能保证每次服务请求都是可用的。
从Zookeeper的实际应用情况来看,在使用Zookeeper获取服务列表时,如果此时Zookeeper集群中的Leader节点宕了,该集群要进行Leader的重新选举,又或者Zookeeper集群中半数节点不可用,都将无法处理请求,所以说Zookeeper不能保证服务可用性。
在大部分分布式环境中,尤其是设计数据存储的场景,数据一致性是首先要保证的,这也是Zookeeper设计CP原则的另一个原因。
但是对于服务发现来说,情况就不太一样了,针对同一个服务,即使注册中心的不同节点保存的服务提供者信息不同,也并不会造成灾难性后果。
因为对于服务消费者来说,能消费才是最重要的,消费者虽然拿到了可能不正确的服务提供者信息,也要胜过因无法获取实例而不去消费,导致系统异常要好。(消费者消费不正确的提供者信息可以进行补偿重试机制)
当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举,问题在于,选举Leader的时间太长,30~120s,而且选举期间整个zk集群是不可用的,这就导致整个选举期间注册服务瘫痪。
尤其在云部署环境下,因为网络问题使得ZK集群失去master节点是大概率事件,虽然服务能最终恢复,但是漫长的选举事件导致注册长期不可用是无法容忍的。
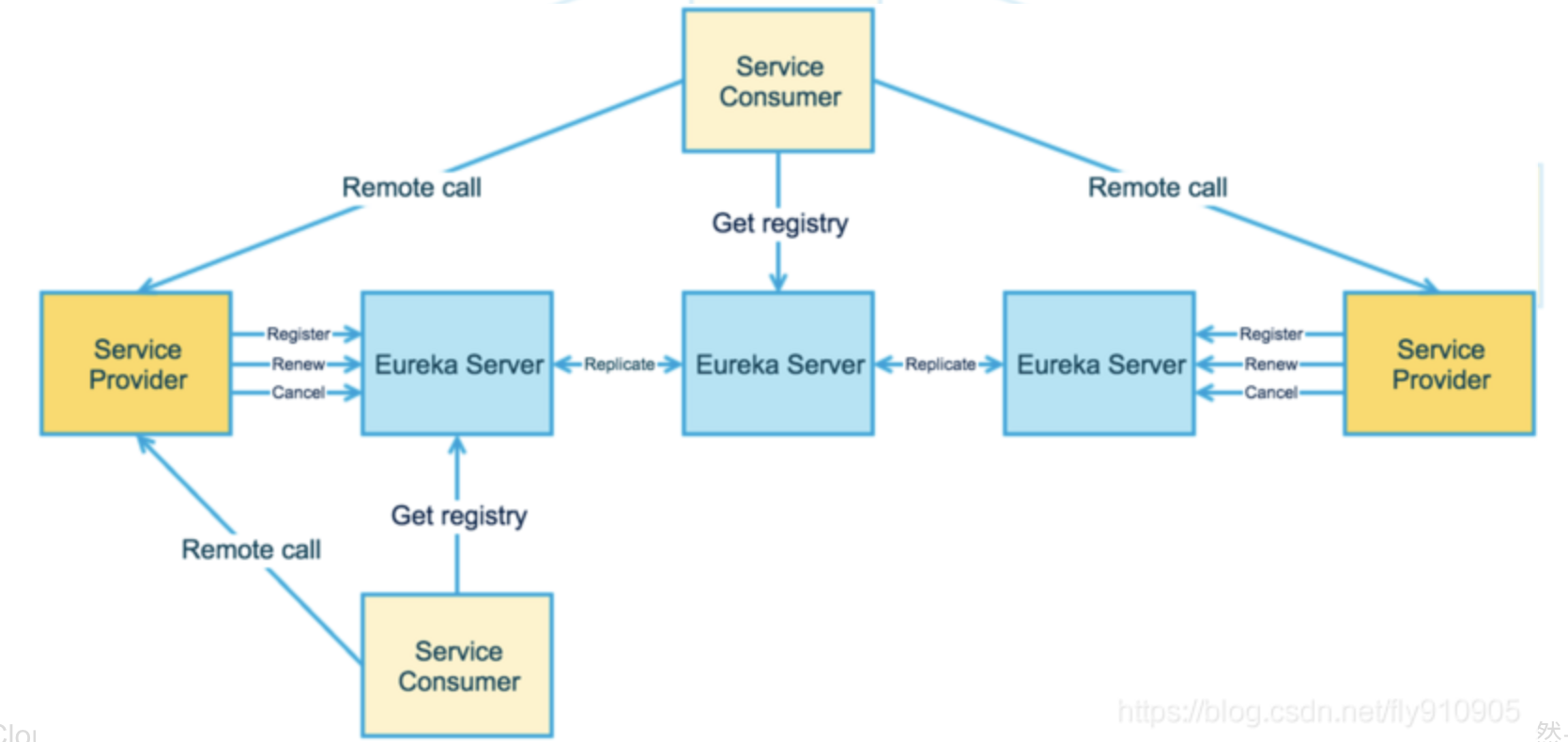
Spring Cloud Netflix 在设计 Eureka的时候遵循的是AP Eureka Server 也可以运行多个实例来构建集群,解决单点问题,但不同于Zookeeper选举leader的过程,Eureka Server采用的是Peer to Peer对等通信。这是一种去中性化的架构,无mater/salve之分,没一个Peer都是对等的。在这种架构风格中,节点通过彼此相互注册来提高可用性,每个节点需要添加一个或多个有效的serviceUrl指向其他节点。每个节点都可以视为其它节点的副本。
在集群环境中如果某台Eureka Server宕机,Eureka Client的请求会自动切换到新的Eureka Server节点上,当宕机的服务器重启恢复后,Eureka会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会在集群中进行复制(replicate to peer)操作,将请求复制到该Eureka Server当前所知的所有节点上。
当一个新的Eureka Server节点启动后,会首先尝试从相邻节点获取所有注册列表信息,并完成初始化。Eureka Server通过getEurekaServiceUrls()方法获取所有的节点,并且会通过心跳契约的方式定时更新。
默认情况下,主要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不能保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册表中移除因为长时间没有收到心跳的服务;
- Eureka仍然能够接受新服务注册和查询请求,但是不会被同步到其它节点上(既保证当前节点可用);
- 当网络稳定时,当前实例新注册的信息会被同步到其它节点上;
因此,Eureka可以很好的应对网络故障导致部分节点失去联系的情况,而不会像Zookeeper那样使得整个注册中心瘫痪。
Nacos是阿里开源的一个产品,主要针对微服务架构中的服务发现、配置管理、服务治理的综合性解决方案; Nacos支持两种方式的注册中心,持久化和非持久化存储服务信息。
- 非持久化直接存储Nacos服务节点的内存中,并且服务节点采用去中心话的思想,服务节点采用Hash分片存储注册信息;
- 持久化使用Raft协议选举Master节点,同样采用半同步机制将数据存储在Leader节点上;
Nacos同时支持持久化和非持久化存储,也就是支持CAP原则中的AP和CP特性,Nacos的CP支持持久化和ZK模式类似。Nacos默认采用AP非持久化,非持久化使用内存存储性能更快,而且Hash分片存储,不利点就是某个服务挂点,可能出现部分部分时间点用失败。因为服务调用本身就是实时的,持久化存储起来意义不大,而且及时变化更合适。
Consul是HashiCorp公司推出的开源工具,用于实现分布式系统的服务发现与配置。Consul使用Go编写,因此具有天然的移植性。
Consul内置了服务注册与发现框架、分布式一致性协议实现、健康检查、Key/Value存储、多数据中心方案。
Consul遵循CAP原理中的CP原则,保证了强一致性和分区容错性,且使用的是Raft算法,比Zookeeper使用的Paxos算法更加简单。虽然保证了强一致性,但是可用性就下降了,例如服务注册的时间会稍微长一些,因为Consul的Raft协议要求必须过半数的节点都写入成功才算成功,在Leader挂掉了之后,重新选出Leader之前会导致Consul不可用。
Consul Template Consul 默认服务调用者需要依赖Consul SDK来发现服务,这就无法保证对应用的零入侵性。
通过Consul Template,可以定时从Consul集群获取最新的服务提供者列表并刷新Load Balance配置,这样对于服务调用者来说,只需要配置一个统一的服务调用地址即可。
Consul强一致性(C)带来的是:
- 服务注册相比Eureka会稍慢一些,因为Consul的Raft协议要求必须半数节点都写入成功才算注册成功;
- Leader挂掉时,重新选举期间整个Consul不可用,保证了强一致性但是牺牲了可用性;
Eureka保证高可用(A)和最终一致性:
- 服务注册相对要快,因为不需要注册信息replicate到其他节点,也不保证注册信息是否replicate成功;
- 当数据存在不一致时,虽然A,B上注册的信息不相同,但是每个Eureka节点依然能够正常的对外提供服务,这会出现查询服务信息时如果A查不到,但请求B就能查的到,保证了可用性但牺牲了一致性;
另一方面,Eureka就是个Servlet程序,跑到Servlet容器中。Consul则是go编写而成。
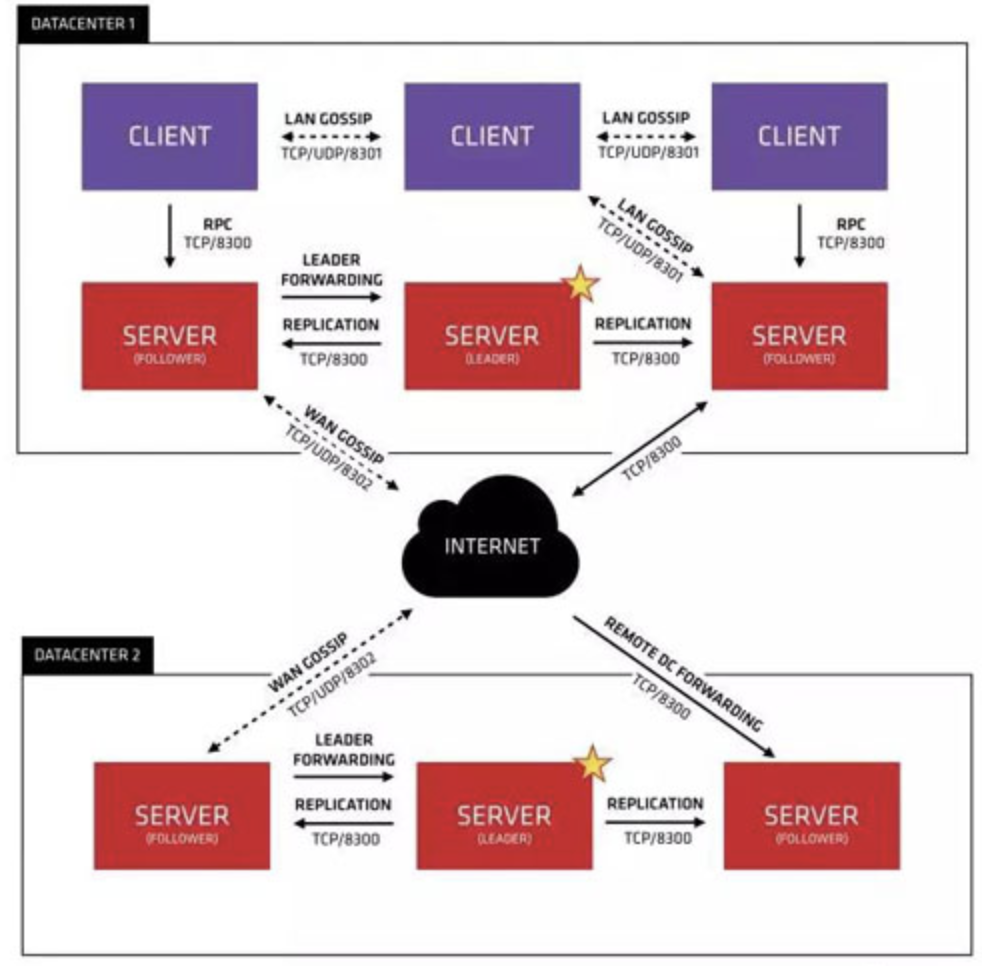
首先Consul支持多数据中心,如图上面有两个DataCenter,他们通过Intenet进行通信,为了提高通信效率,只有Server节点参与到了跨数据中心通信。
在Consul单数据中心中,节点分为Master和Client两种(它们也称为Agent节点),Master节点用于存储数据,Client节点负责健康状态检查和转发数据请求给Master节点。
Master节点采用Raft算法保证多个Master节点数据一致性,Master节点们分为一个Leader和多个Follower,Leader节点会将数据同步给所有的Follower节点,当Leader节点宕掉时会采用选举机制重新选举Leader节点,但是选举期间是不能提供服务的(也就是不能保证可用性)。
集群内的Consul节点通过gossip协议维护成员关系,也就是说任一节点都能知道整个Consul集群中还有其他哪些节点,还包括这些节点的信息,如这个节点是Master节点还是Client节点。
单个数据中心的gossip协议(流言协议),同时使用UDP和TCP进行通信,使用端口是8301。跨数据中心的gossip协议,也同时采用UDP和TCP协议进行通讯,使用端口是8302.
集群的读写请求可以直接发给Server,也可以发给Client使用RPC转发给Master节点,这些请求最终会通过Mstaer节点同步给所有Leader节点上。集群内的数据读写和复制采用TCP的8300端口完成。
check必须是Script、HTTP、TCP、TTL四中类型的一种
Script Check
通过执行外部应用进行健康状态检查;
HTTP Check
这种检查将按照预设的时间间隔创建一个HTTP get请求,相应状态码必须为2XX系列,在SpringCloud中通常使用HTTP Check的方式;
TCP Check
根据设置的IP/端口创建一个TCP连接,连接成功为Success,失败是Critical状态;
TTL Check
这种Checks为给定的TTL保留了最后一种状态,Checks的状态必须通过HTTP接口周期性跟新状态,如果外部接口没有更新状态,那么状态就会被认为不正常; 这种机制,在概念上类似“死人开关”,需要服务周期性汇报监控状态。在高版本的Dubbo中扩展了Consul使用的是TTL Check机制;
//下载二进制包与解压
wget https://releases.hashicorp.com/consul/1.5.1/consul_1.5.1_linux_amd64.zip
unzip consul_1.5.1_linux_amd64.zip -d /usr/local/bin
//修改变量环境信息
vi /etc/profile
export CONSUL_HOME=/usr/local/bin/consul
export PATH=$PATH:CONSUL_HOME
// 使用环境变量配置生效
source /etc/profile
//测试
consul --version| 参数名称 | 用途 |
|---|---|
| -server | 指定运行模式为服务器,每个Consul集群至少有1个Server,正常不超过5个 |
| -client | 表示Consul指定客户端的IP地址,默认127.0.0.1 |
| -bootstrap-expect | 预期服务器集群的数量 |
| -data-dir | 存储数据目录,该目录的数据在重启Consul后依然生效,目录需要赋予Consul启动用户权限 |
| -node | 当前服务器在集群中的名称,默认是服务器的名称 |
| -ui | 启动当前服务器内部的WebUI服务器和控制台界面 |
| -join | 指定当前服务器启动时,加入另一个代理服务器的地址 |
演示服务器:10.211.55.6,10.211.55.7,10.211.55.8
//10.211.55.6
consul agent -server -ui -bootstrap-expect=3 -data-dir=/data/consul -node=agent-1 -client=0.0.0.0 -bind=10.211.55.6 -datacenter=dc1
//10.211.55.7
consul agent -server -ui -bootstrap-expect=3 -data-dir=/data/consul -node=agent-2 -client=0.0.0.0 -bind=10.211.55.7 -datacenter=dc1 -join 10.211.55.6
//10.211.55.8
consul agent -server -ui -bootstrap-expect=3 -data-dir=/data/consul -node=agent-3 -client=0.0.0.0 -bind=10.211.55.8 -datacenter=dc1 -join 10.211.55.6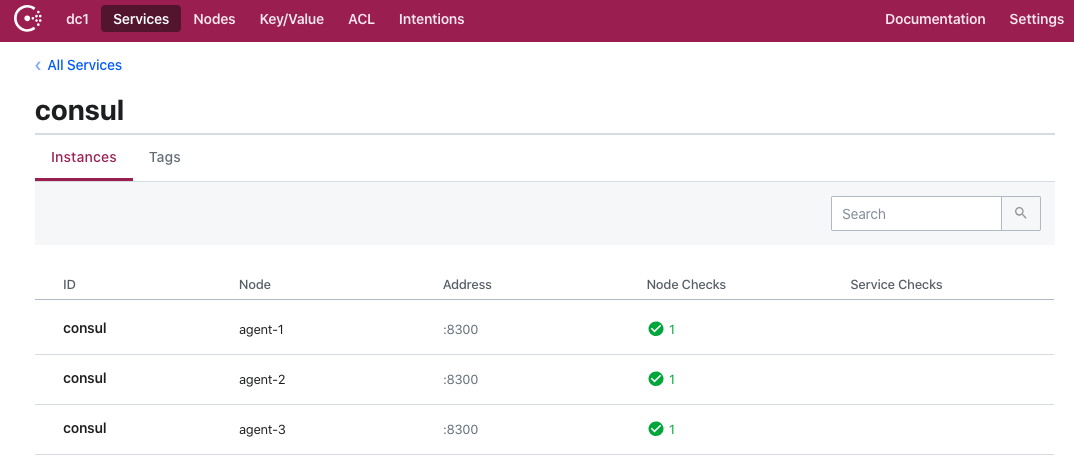
Conusl提供了一个Key/Value Store可以用于动态配置;
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
<version>2.1.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-config</artifactId>
<version>2.1.4.RELEASE</version>
</dependency>application.properties
spring.profiles.active=dev
spring.application.name=consul-config
server.port=8081bootstrap.properties
#配置consul地址
spring.cloud.consul.host=10.211.55.8
#配置consul端口
spring.cloud.consul.port=8500
#指定服务的 consul service name
spring.cloud.consul.discovery.serviceName=consul-config
#启动consul配置中心
spring.cloud.consul.config.enabled=true
#配置基本文件格式
spring.cloud.consul.config.format=yaml
#配置基本文件,默认值config
spring.cloud.consul.config.prefix=config
#profileSeparator设置用于使用配置文件在属性源中分隔配置文件名称的分隔符的值
spring.cloud.consul.config.profile-separator=:
#表示 consul 上面的 KEY 值(或者说文件的名字),默认是 data
spring.cloud.consul.config.data-key=data
# 健康检查url
spring.cloud.consul.discovery.health-check-url=http://10.211.55.2:8081/actuator/health
# 健康检查的频率, 默认 10 秒
spring.cloud.consul.discovery.health-check-interval=10s
# 健康检查失败多长时间后,取消注册
spring.cloud.consul.discovery.health-check-critical-timeout=5s@SpringBootApplication
@EnableDiscoveryClient //让注册中心进行服务发现,将服务注册到服务组件上
public class SpringcloudConsulConfigSampleApplication {
public static void main(String[] args) {
SpringApplication.run(SpringcloudConsulConfigSampleApplication.class, args);
}
}4.添加配置实例,用@RefreshScope声明自动更新配置,当配置变更时,将会通过Spring Cloud Bus发送RefreshRemoteApplicationEvent事件给相关程序,在RefreshListener中,开始对于配置的刷新;
@RestController
@RequestMapping("/consul")
@RefreshScope // 如果参数变化,自动刷新
public class ConsulConfigCenterController {
@Value("${config.info}")
private String configInfo;
@GetMapping("/config/get")
public Object getItem() {
return configInfo;
}
}创建目录:config/consul-config:dev/data(需要和bootstrap.properties配置的内容一致)
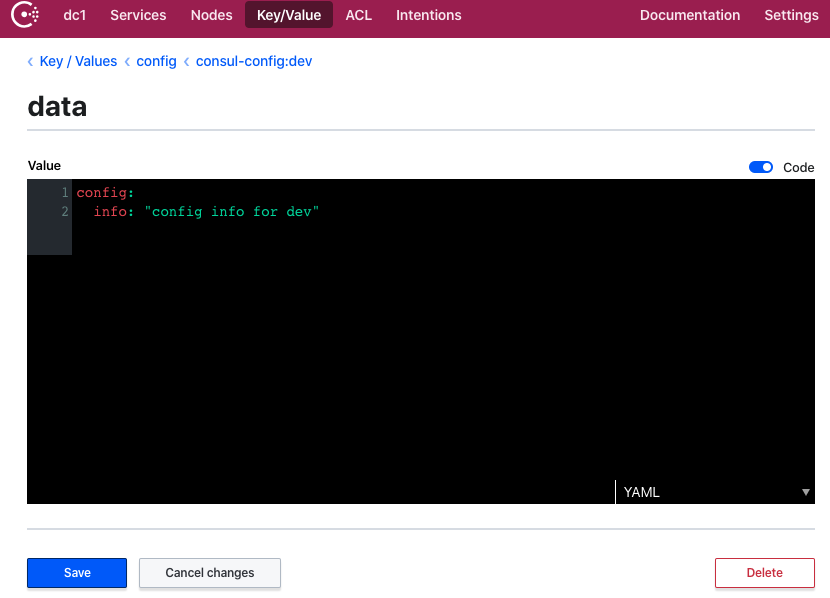
% curl -i -l http://127.0.0.1:8081/consul/config/get
HTTP/1.1 200
Content-Type: text/plain;charset=UTF-8
Content-Length: 19
Date: Mon, 28 Dec 2020 08:49:36 GMT
config info for dev