这些变换虽然功能各有不同,但实质上都是针对事件序列的处理和再发送。而在RxJava的内部,它们是基于同一个基础的变换方法:lift()。
首先看一下lift() 的内部实现(仅核心代码):
// 注意:这不是 lift() 的源码,而是将源码中与性能、兼容性、扩展性有关的代码剔除后的核心代码。
public <R> Observable<R> lift(Operator<? extends R, ? super T> operator) {
return Observable.create(new OnSubscribe<R>() {
@Override
public void call(Subscriber subscriber) {
Subscriber newSubscriber = operator.call(subscriber);
newSubscriber.onStart();
onSubscribe.call(newSubscriber);
}
});
}这段代码很有意思:它生成了一个新的Observable并返回,而且创建新Observable所用的参数OnSubscribe的回调方法call()中的实现竟然看起来和前面讲过的Observable.subscribe()一样! 然而它们并不一样哟~不一样的地方关键就在于第二行onSubscribe.call(subscriber)中的onSubscribe` 所指代的对象不同:
-
subscribe()中这句话的onSubscribe指的是Observable中的onSubscribe对象,这个没有问题,但是lift()之后的情况就复杂了点。 -
当含有
lift()时:lift()创建了一个Observable后,加上之前的原始Observable,已经有两个Observable了;- 而同样地,新
Observable里的新OnSubscribe加上之前的原始Observable中的原始OnSubscribe,也就有了两个OnSubscribe; - 当用户调用经过
lift()后的Observable的subscribe()的时候,使用的是lift()所返回的新的Observable,于是它所触发的onSubscribe.call(subscriber),也是用的新Observable中的新OnSubscribe,即在lift()中生成的那个OnSubscribe; - 而这个新
OnSubscribe的call()方法中的onSubscribe,就是指的原始Observable中的原始OnSubscribe,在这个call()方法里,新OnSubscribe利用operator.call(subscriber)生成了一个新的Subscriber(Operator就是在这里,通过自己的call()方法将新Subscriber和原始Subscriber进行关联,并插入自己的『变换』代码以实现变换),然后利用这个新Subscriber向原始Observable进行订阅。 这样就实现了lift()过程,有点像一种代理机制,通过事件拦截和处理实现事件序列的变换。
精简掉细节的话,也可以这么说:在Observable执行了lift(Operator)方法之后,会返回一个新的Observable,这个新的Observable会像一个代理一样,负责接收原始的Observable 发出的事件,并在处理后发送给Subscriber。
如果你更喜欢具象思维,可以看图:

举一个具体的Operator的实现。下面这是一个将事件中的Integer对象转换成String的例子,仅供参考:
observable.lift(new Observable.Operator<String, Integer>() {
@Override
public Subscriber<? super Integer> call(final Subscriber<? super String> subscriber) {
// 将事件序列中的 Integer 对象转换为 String 对象
return new Subscriber<Integer>() {
@Override
public void onNext(Integer integer) {
subscriber.onNext("" + integer);
}
@Override
public void onCompleted() {
subscriber.onCompleted();
}
@Override
public void onError(Throwable e) {
subscriber.onError(e);
}
};
}
});讲述
lift()的原理只是为了让你更好地了解RxJava,从而可以更好地使用它。然而不管你是否理解了lift()的原理,RxJava都不建议开发者自定义Operator来直接使用lift(),而是建议尽量使用已有的lift()包装方法(如map()、flatMap()等)进行组合来实现需求,因为直接使用lift()非常容易发生一些难以发现的错误。
在不指定线程的情况下,RxJava遵循的是线程不变的原则,即在哪个线程调用subscribe()方法就在哪个线程生产事件; 在哪个线程生产事件,就在哪个线程消费事件。也就是说事件的发出和消费都是在同一个线程的。观察者模式本身的目的就是『后台处理,前台回调』的异步机制,因此异步对于RxJava是至关重要的。而要实现异步,则需要用到RxJava的另一个概念:Scheduler。
在RxJava中,Scheduler相当于线程控制器,RxJava通过它来指定每一段代码应该运行在什么样的线程。RxJava已经内置了几个Scheduler,它们已经适合大多数的使用场景:
Schedulers.immediate(): 直接在当前线程运行,相当于不指定线程。这是默认的Scheduler。Schedulers.newThread(): 总是启用新线程,并在新线程执行操作。Schedulers.io(): I/O 操作(读写文件、读写数据库、网络信息交互等)所使用的Scheduler。行为模式和newThread()差不多,区别在于io()的内部实现是是用一个无数量上限的线程池,可以重用空闲的线程,因此多数情况下io()比newThread()更有效率。不要把计算工作放在io()中,可以避免创建不必要的线程。Schedulers.computation(): 计算所使用的Scheduler。这个计算指的是CPU密集型计算,即不会被I/O等操作限制性能的操作,例如图形的计算。这个Scheduler使用的固定的线程池,大小为CPU核数。不要把I/O操作放在computation()中,否则I/O操作的等待时间会浪费CPU。- 另外,
Android还有一个专用的AndroidSchedulers.mainThread(),它指定的操作将在Android主线程运行。
有了这几个Scheduler,就可以使用subscribeOn()和observeOn()两个方法来对线程进行控制了。subscribeOn()指定subscribe()所发生的线程,即Observable.OnSubscribe()被激活时所处的线程或者叫做事件产生的线程。observeOn()指定Subscriber所运行在的线程或者叫做事件消费的线程。
Observable.just("Hello ", "World !")
.subscribeOn(Schedulers.io()) // 指定 subscribe() 发生在 IO 线程,可以理解成数据的获取是在io线程
.observeOn(AndroidSchedulers.mainThread())// 指定 Subscriber 的回调发生在主线程,可以理解成数据的消费时在主线程
.subscribe(new Action1<String>() {
@Override
public void call(String s) {
Log.i("@@@", s);
}
});上面这段代码中,subscribeOn(Schedulers.io())的指定会让创建的事件的内容Hello 、World !将会在IO线程发出;
而由于observeOn(AndroidScheculers.mainThread()) 的指定,因此subscriber()方法设置后的回调中内容的打印将发生在主线程中。
事实上,这种在subscribe()之前写上两句subscribeOn(Scheduler.io())和observeOn(AndroidSchedulers.mainThread())的使用方式非常常见,它适用于多数的后台线程取数据,主线程显示的程序策略。
RxJava的Scheduler API很方便,也很神奇(加了一句话就把线程切换了,怎么做到的?而且subscribe()不是最外层直接调用的方法吗,它竟然也能被指定线程?)。然而Scheduler的原理需要放在后面讲,因为它的原理是以下一节《变换》的原理作为基础的。
好吧这一节其实我屁也没说,只是为了让你安心,让你知道我不是忘了讲原理,而是把它放在了更合适的地方。
能不能多切换几次线程?答案是:能。
因为observeOn()指定的是Subscriber的线程,而这个Subscriber并不是(严格说应该为『不一定是』,但这里不妨理解为『不是』)subscribe() 参数中的Subscriber,而是observeOn()执行时的当前Observable所对应的Subscriber,即它的直接下级Subscriber。
换句话说observeOn() 指定的是它之后的操作所在的线程。因此如果有多次切换线程的需求,只要在每个想要切换线程的位置调用一次observeOn()即可。
上代码:
Observable.just(1, 2, 3, 4) // IO 线程,由 subscribeOn() 指定
.subscribeOn(Schedulers.io())
.observeOn(Schedulers.newThread())
.map(mapOperator) // 新线程,由 observeOn() 指定
.observeOn(Schedulers.io())
.map(mapOperator2) // IO 线程,由 observeOn() 指定
.observeOn(AndroidSchedulers.mainThread)
.subscribe(subscriber); // Android 主线程,由 observeOn() 指定如上,通过observeOn()的多次调用,程序实现了线程的多次切换。
不过,不同于observeOn(),subscribeOn()的位置放在哪里都可以,但它是只能调用一次的。
其实,subscribeOn()和observeOn()的内部实现,也是用的lift()。
具体看图(不同颜色的箭头表示不同的线程,subscribeOn()原理图:
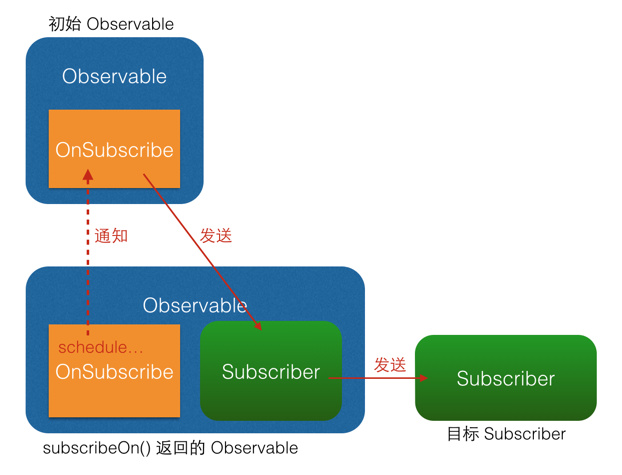
observeOn()原理图:
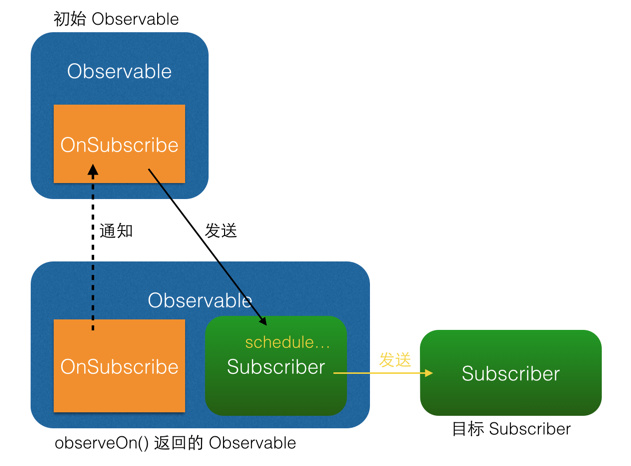
从图中可以看出,subscribeOn()和observeOn()都做了线程切换的工作(图中的schedule...部位)。不同的是,subscribeOn()的线程切换发生在OnSubscribe中,即在它通知上一级 OnSubscribe时,这时事件还没有开始发送,因此subscribeOn()的线程控制可以从事件发出的开端就造成影响;而observeOn()的线程切换则发生在它内建的Subscriber中,即发生在它即将给下一级Subscriber发送事件时,因此observeOn()控制的是它后面的线程。
最后,我用一张图来解释当多个subscribeOn()和observeOn()混合使用时,线程调度是怎么发生的(由于图中对象较多,相对于上面的图对结构做了一些简化调整):
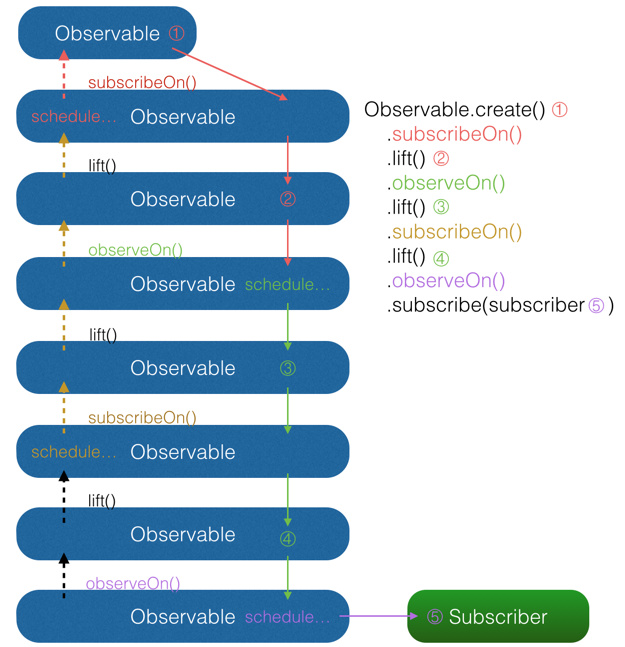
图中共有5处含有对事件的操作。由图中可以看出,①和②两处受第一个subscribeOn()影响,运行在红色线程;
③和④处受第一个observeOn()的影响,运行在绿色线程;
⑤处受第二个 onserveOn()影响,运行在紫色线程;而第二个subscribeOn(),由于在通知过程中线程就被第一个subscribeOn() 截断,因此对整个流程并没有任何影响。
这里也就回答了前面的问题:当使用了多个subscribeOn()的时候,只有第一个subscribeOn()起作用。
在前面讲Subscriber的时候,提到过Subscriber的onStart()可以用作流程开始前的初始化。然而onStart()由于在subscribe()发生时就被调用了,因此不能指定线程,而是只能执行在subscribe()被调用时的线程。这就导致如果onStart()中含有对线程有要求的代码(例如在界面上显示一个ProgressBar,这必须在主线程执行),将会有线程非法的风险,因为有时你无法预测subscribe()将会在什么线程执行。
而与Subscriber.onStart()相对应的,有一个方法Observable.doOnSubscribe()。
它和Subscriber.onStart()同样是在subscribe()调用后而且在事件发送前执行,但区别在于它可以指定线程。
默认情况下,doOnSubscribe()执行在subscribe()发生的线程;而如果在doOnSubscribe()之后有subscribeOn()的话,它将执行在离它最近的subscribeOn()所指定的线程。
示例代码:
Observable.create(onSubscribe)
.subscribeOn(Schedulers.io())
.doOnSubscribe(new Action0() {
@Override
public void call() {
progressBar.setVisibility(View.VISIBLE); // 需要在主线程执行
}
})
.subscribeOn(AndroidSchedulers.mainThread()) // 指定主线程
.observeOn(AndroidSchedulers.mainThread())
.subscribe(subscriber);如上,在doOnSubscribe()的后面跟一个subscribeOn(),就能指定准备工作的线程了。
RxJava辣么好,难道他就没有缺点吗?当然有那就是使用越来越多的订阅,内存开销也会变得很大,稍不留神就会出现内存溢出的情况。我们可以用RxJava实现基本任何功能,但是你并不能这么做,你要明白什么时候需要用它,而什么时候没必要用它,不要一味的把功能都有RxJava来实现。
至于上面提到的2.0版本,有关它的区别请见:
What's different in 2.0
更多内容请看下一篇文章RxJava详解(四)

之前Google发布agera,它在Github上的介绍是:Reactive Programming for Android
既然是响应式编程框架,其核心思想肯定和RxJava也是类似的。
Agera中核心也是关于事件流(数据流)的处理,可以转换数据、可以指定数据操作函数在那个线程执行。
而Agera和RxJava不一样的地方在于,Agera提供了一个新的事件响应和数据请求的模型,被称之为Push event, pull data。也就是一个事件发生了,会通过回调来主动告诉你,你关心的事件发生了。然后你需要主动的去获取数据,根据获取到的数据做一些操作。而RxJava在事件发生的时候,已经带有数据了。为了支持 Push event pull data模型,Agera中有个新的概念 — Repository。Repository翻译过来也就是数据仓库,是用来提供数据的,当你收到事件的时候,通过Repository来获取需要的数据。 这样做的好处是,把事件分发和数据处理的逻辑给分开了,事件分发做的事情比较少,事件分发就比较高效,当你收到事件后,根据当前的状态如果发现这个时候,数据已经无效了,则你根本不用请求数据,这样数据也就不用去处理和转换了。这样可以避免无用的数据计算,而有用的数据计算也可以在你需要的时候才去计算。
同样,在多线程环境下,使用push event pull data模型,可能当你收到事件通知的时候,你只能获取到最新的数据,无法去获取历史数据了。设计就是这样考虑的,因为在Android开发中大部分的数据都是用来更新UI的,这个时候你根本不需要旧的数据了,只要最新的就够了。
Agera相对比较简单,并且是一个专业为Android平台打造的响应式编程框架。但是如果你熟悉了RxJava你会发现其用起来会有点不舒服,特别是还要主动的获取数据略感不爽(虽然提高了事件分发的效率)。
总之,现在看来RxJava支持的比较全面,但是会略显笨重,而Agera是一个专门为Android平台设计的响应式编程框架,比较轻巧,当然支持的并不是很全面。可以根据自己的喜好来选择.
但是从个人观点来看Agera比起来RxJava还是相差几个版本。当然这是我的片面之词,有关更多信息请看Question: what's the relation to RxJava?
参考:
- RxJava Wiki
- Grokking RxJava, Part 1: The Basics
- NotRxJava
- When Not to Use RxJava
- 给 Android 开发者的 RxJava 详解
- Google Agera 从入门到放弃
- 邮箱 :charon.chui@gmail.com
- Good Luck!