所谓线程池,就是将多个线程放在一个池子里面(所谓池化技术),然后需要线程的时候不是创建一个线程,而是从线程池里面获取一个可用的线程,然后执行我们的任务。线程池的关键在于它为我们管理了多个线程,我们不需要关心如何创建线程,我们只需要关系我们的核心业务,然后需要线程来执行任务的时候从线程池中获取线程。任务执行完之后线程不会被销毁,而是会被重新放到池子里面,等待机会去执行任务。
-
在什么情况下使用线程池?
- 单个任务处理的时间比较短
- 将要处理的任务的数量大
假设一个服务器完成一项任务所需时间为:
T1创建线程时间,T2在线程中执行任务的时间,T3销毁线程时间。如果:T1 + T3远大于T2,则可以采用线程池,以提高服务器性能。 -
一个线程池包括以下四个基本组成部分:
- 线程池管理器(
ThreadPool):用于创建并管理线程池,包括创建线程池,销毁线程池,添加新任务 - 工作线程(
PoolWorker):线程池中的线程,在没有任务时处于等待状态,可以循环的执行任务 - 任务接口(
Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等 - 任务队列(
TaskQueue):用于存放没有处理的任务。提供一种缓冲机制。
- 线程池管理器(
-
使用线程池的好处:
- 降低资源消耗。通过重复利用减少在创建和销毁线程上所花的时间以及系统资源的开销
- 提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源, 还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。如不使用线程池,有可能造成系统创建大量线程而导致消耗完系统内存以及”过度切换”。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
-
工作流程
线程池的任务就在于负责这些线程的创建,销毁和任务处理参数传递、唤醒和等待。- 创建若干线程,置入线程池
- 任务达到时,从线程池取空闲线程
- 取得了空闲线程,立即进行任务处理
- 否则新建一个线程,并置入线程池,并执行上一步
- 如果创建失败或者线程池已满,根据设计策略选择返回错误或将任务置入处理队列,等待处理
- 销毁线程池
-
风险
虽然线程池是构建多线程应用程序的强大机制,但使用它并不是没有风险的。 用线程池构建的应用程序容易遭受任何其它多线程应用程序容易遭受的所有并发风险,诸如同步错误和死锁, 它还容易遭受特定于线程池的少数其它风险,诸如与池有关的死锁、资源不足和线程泄漏。 -
资源不足
线程池的一个优点在于:相对于其它替代调度机制而言,它们通常执行的很好。但只有恰当地调整了线程池大小时才是这样的。 线程消耗包括内存和其它系统资源在内的大量资源。除了Thread对象所需的内存之外,每个线程都需要两个可能很大的执行调用堆栈。 除此以外JVM可能会为每个Java线程创建一个本机线程,这些本机线程将消耗额外的系统资源。最后虽然线程之间切换的调度开销很小, 但如果有很多线程,环境切换也可能严重地影响程序的性能。 如果线程池太大,那么被那些线程消耗的资源可能严重地影响系统性能。在线程之间进行切换将会浪费时间, 而且使用超出比您实际需要的线程可能会引起资源匮乏问题,因为池线程正在消耗一些资源,而这些资源可能会被其它任务更有效地利用。 除了线程自身所使用的资源以外,服务请求时所做的工作可能需要其它资源,例如JDBC连接、套接字或文件。 这些也都是有限资源,有太多的并发请求也可能引起失效,例如不能分配JDBC连接。
java.uitl.concurrent.ThreadPoolExecutor类是线程池中最核心的一个类:
public class ThreadPoolExecutor extends AbstractExecutorService {
.....
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);
...
}上面构造器中各参数的含义:
-
corePoolSize:用来表示线程池中的核心线程的数量,也可以称为可闲置的线程数量。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务, 除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中; -
maximumPoolSize:来表示线程池中最多能够创建的线程数量。这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程; -
keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0; -
unit:参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:TimeUnit.DAYSTimeUnit.HOURSTimeUnit.MINUTESTimeUnit.SECONDSTimeUnit.MILLISECONDSTimeUnit.MICROSECONDSTimeUnit.NANOSECONDS
-
workQueue:一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:ArrayBlockingQueue:基于数组的先进先出队列,此队列创建时必须指定大小;LinkedBlockingQueue:基于链表的先进先出队列,如果创建时没有指定此队列大小,则默认为Integer.MAX_VALUE;SynchronousQueue:这个队列比较特殊,它不会保存提交的任务,而是将直接新建一个线程来执行新来的任务。PriorityBlockingQuene:具有优先级的无界阻塞队列
-
threadFactory:线程工厂,主要用来创建线程 -
handler:表示当拒绝处理任务时的策略,有以下四种取值:ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
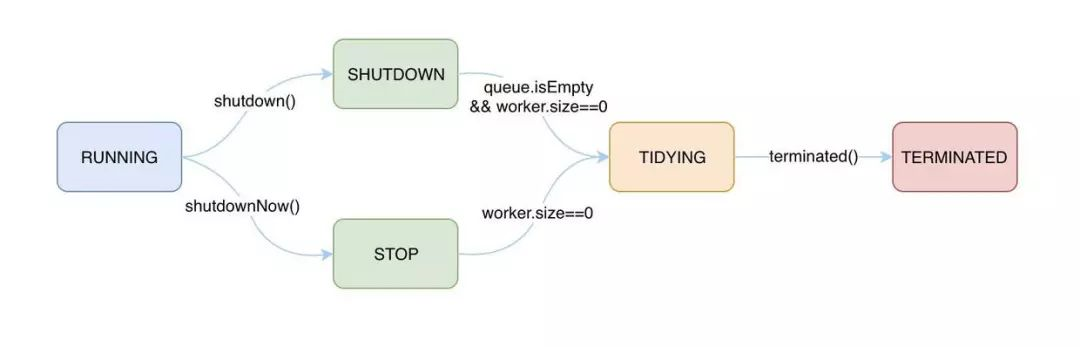
ThreadPoolExecutor中定义了一个volatile变量,另外定义了几个static final变量表示线程池的各个状态:
volatile int runState;表示当前线程池的状态,它是一个volatile变量用来保证线程之间的可见性static final int RUNNING = -1;此状态下,线程池可以接受新的任务,也可以处理阻塞队列中的任务。执行shutdown()方法可进入待关闭(SHUTDOWN)状态,执行shutdownNow()方法可进入停止(STOP)状态。static final int SHUTDOWN = 0;如果调用了shutdown()方法,则线程池处于SHUTDOWN状态,此时线程池不能够接受新的任务,它会等待所有任务执行完毕static final int STOP = 1;如果调用了shutdownNow()方法,则线程池处于STOP状态,此时线程池不能接受新的任务,并且会去尝试终止正在执行的任务;static final int TIDYING = 2;此状态下,所有任务都已经执行完毕,且没有工作线程。执行terminated()方法进入终止(TERMINATED)状态。该状态表示线程池对线程进行整理优化;static final int TERMINATED = 3;当线程池处于SHUTDOWN或STOP状态,并且所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为TERMINATED状态。此状态下,线程池完全终止,并完成了所有资源的释放。
不过在java doc中,并不提倡我们直接使用ThreadPoolExecutor,而是使用Executors类中提供的几个静态方法来创建线程池:
Executors.newCachedThreadPool();//创建一个可缓存线程池,缓冲池容量大小为Integer.MAX_VALUEExecutors.newSingleThreadExecutor();//创建容量为1的缓冲池,即线程池中每次只有一个线程工作,单线程串行执行任务,Executors.newFixedThreadPool(int);//创建固定容量大小的缓冲池,固定数量的线程池,没提交一个任务就是一个线程,直到达到线程池的最大数量,然后后面进入等待队列直到前面的任务完成才继续执行Executors.newScheduleThreadExecutor();// 大小无限制的线程池,能按时间计划来执行任务,允许用户设定计划执行任务的时间。在实际的业务场景中可以使用该线程池定期的同步数据。
这几个方法的具体实现:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}从它们的具体实现来看,它们实际上也是调用了ThreadPoolExecutor,只不过参数都已配置好了:
newFixedThreadPool创建的线程池corePoolSize和maximumPoolSize值是相等的,它使用的LinkedBlockingQueue;newSingleThreadExecutor将corePoolSize和maximumPoolSize都设置为1,也使用的LinkedBlockingQueue;newCachedThreadPool将corePoolSize设置为0,将maximumPoolSize设置为Integer.MAX_VALUE,使用的SynchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。newScheduledThreadPool:maximumPoolSize``Integer.MAX_VALUE使用DelayedWorkQueue())。
实际中,如果Executors提供的三个静态方法能满足要求,就尽量使用它提供的三个方法,因为自己去手动配置ThreadPoolExecutor的参数有点麻烦,要根据实际任务的类型和数量来进行配置。
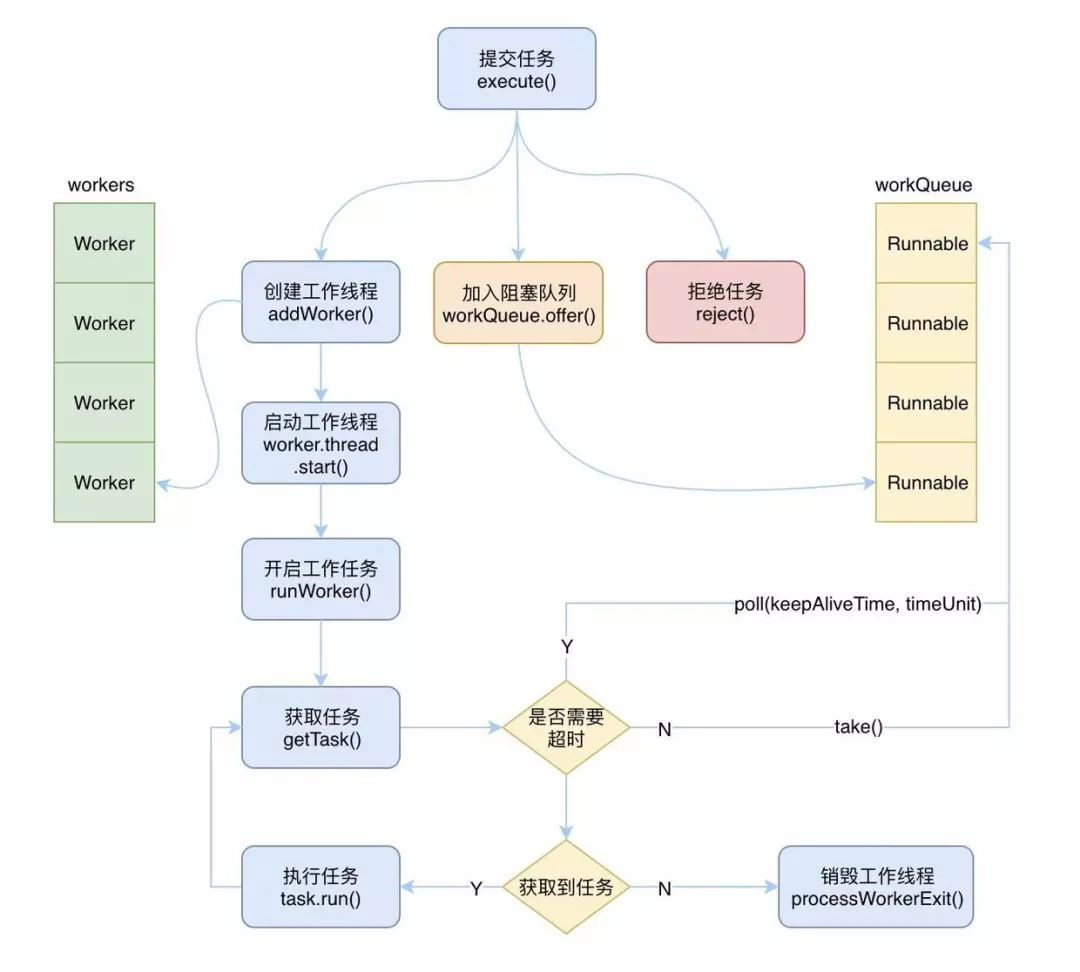 整个过程可以拆分成以下几个部分:
整个过程可以拆分成以下几个部分:
-
提交任务
当向线程池提交一个新的任务时,线程池有三种处理情况,分别是:创建一个工作线程来执行该任务、将任务加入阻塞队列、拒绝该任务。
提交任务的过程也可以拆分成以下几个部分:
- 当工作线程数小于核心线程数时,直接创建新的核心工作线程。
- 当工作线程数大于核心线程数时,就需要尝试将任务添加到阻塞队列中去。
- 如果能够加入成功,说明队列还没满,那么就需要做以下的二次校验来保证添加进去的任务能够成功被执行。
- 验证当前线程池中的运行状态,如果是非RUNNING状态,则需要将任务从阻塞队列中移除,然后拒绝该任务。
- 验证当前线程池中的工作线程的个数,如果是0,则需要主动添加一个空工作线程来执行刚刚添加到阻塞队列中的任务。
- 如果加入失败,说明队列已经满了,这时就需要创建新的临时工作线程来执行任务。
- 如果创建成功,则直接执行该任务。
- 如果创建失败,说明工作线程数已经等于最大线程数了,只能拒绝该任务了。
-
创建工作线程
创建工作线程需要做一系列的判断,需要确保当前线程池可以创建新的线程之后,才能创建。
首先,当线程池的状态是SHUTDOWN或者STOP时,不能创建新的线程。
其次,当线程工厂创建线程失败时,也不能创建新的线程。
第三,拿当前工作线程的数量与核心线程数、最大线程数进行比较,如果前者大于后者的话,也不允许创建。除此之外,线程池会尝试通过CAS来自增工作线程的个数,如果自增成功了,则会创建新的工作线程,即Worker对象。
然后加锁进行二次验证是否能够创建工作线程,如果最后创建成功,则会启动该工作线程。
-
启动工作线程
当工作线程创建成功后,也就是Worker对象已经创建好了,这时就需要启动该工作线程,让线程开始干活了,Worker对象中关联着一个Thread,所以要启动工作线程的话,只要通过worker.thread.start()来启动该线程即可。
启动完了之后,就会执行Worker对象的run方法,因为Worker实现了Runnable接口,所以本质上Worker也是一个线程。
通过线程start开启之后就会调用到Runnable的run方法,在Worker对象的run方法中,调用了runWorker(this)方法,也就是把当前对象传递给了runWorker()方法,让它来执行。
-
获取任务并执行
在runWorker方法被调用之后,就是执行具体的任务了,首先需要拿到一个可以执行的任务,而Worker对象中默认绑定了一个任务,如果该任务不为空的话,那么就是直接执行。
执行完了之后,就会去阻塞队列中获取任务来执行。
获取任务的过程则需要考虑当前工作线程的个数:
- 如果工作线程数大于核心线程数,那么就需要通过poll(keepAliveTime, timeUnit)来获取,因为这时需要对闲置线程进行超时回收。
- 如果工作线程数小于等于核心线程数,那么就可以通过take()来获取了。因为这时所有的线程都是核心线程,不需要进行回收,前提是没有设置allowCoreThreadTimeOut(允许核心线程超时回收)为true。
有两种方式:
Executor.execute(Runnable command);ExecutorService.submit(Callable<T> task);
- 首次通过
workCountof()获知当前线程池中的线程数,如果小于corePoolSize, 就通过addWorker()创建线程并执行该任务;否则,将该任务放入阻塞队列; - 如果能成功将任务放入阻塞队列中,如果当前线程池是非RUNNING状态,则将该任务从阻塞队列中移除,然后执行
reject()处理该任务;如果当前线程池处于RUNNING状态,则需要再次检查线程池(因为可能在上次检查后,有线程资源被释放),是否有空闲的线程;如果有则执行该任务; - 如果不能将任务放入阻塞队列中,说明阻塞队列已满;那么将通过
addWoker()尝试创建一个新的线程去执行这个任务;如果addWoker()执行失败,说明线程池中线程数达到maxPoolSize,则执行reject()处理任务;
会将提交的Callable任务会被封装成了一个FutureTask对象,FutureTask类实现了Runnable接口,这样就可以通过Executor.execute()提交FutureTask到线程池中等待被执行,最终执行的是FutureTask的run方法;
比较:
两个方法都可以向线程池提交任务,execute()方法的返回类型是void,它定义在Executor接口中, 而submit()方法可以返回持有计算结果的Future对象,它定义在ExecutorService接口中,它扩展了Executor接口,其它线程池类像ThreadPoolExecutor和ScheduledThreadPoolExecutor都有这些方法。
ThreadPoolExecutor提供了两个方法,用于线程池的关闭:
shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务
- 邮箱 :charon.chui@gmail.com
- Good Luck!