Let's play Hangman! Now you are the one who give word for AI to guess!
If you haven't heard about Hangman, play it here
Also there are a bunch of analysis of best strategies here
In command line environment, run
python main.py --lives 6 --train_set "words_250000_train.txt"
- lives is the number of fail guesses assigned by you. If AI can't guess the correct word within lives fails, the AI loss.
- train_set is the path of training set. Since AI needs read english words to learn how to guess, train_set should be a .txt file contains only english words each line. Default training set contains 250000 words. Testing words may or may not appear in the training set.
-
Guess the first letters. In this step, the algorithm will make the guess based on the letter frequency in the corresponding word group. Word group here refers to all the words of the same length in the training set. For example, if the train set is ["abc", "de", "adf"] then we have two word groups: length == 2 group and length == 3 group. In length == 2 group, "a" has the highest frequency, then our first guess will be "a" . If the letter with the highest frequency is not in the hidden word, the algorithm will continue to guess the letter with the second-highest frequency ... This step will keep going on until the algorithm has made a valid guess.
-
Guess other letters by 2-gram. After divided all words into different groups, I calculated the frequency of the 2-grams in each group. Starting from the first letter guessed in the first step, the algorithm will calculate all the 2-grams contains the letter and chose the 2-gram with the highest frequency. This step will keep going on until the algorithm has made a valid guess. Use LSTM model to make predictions. There is also a chance that no matched 2-gram will be found. In this case, I pre-trained an LSTM model to fill in the remaining blanks. The main benefit of the model is to introduce uncertainty so that we can make predictions other than combinations we have seen in the training set. The structure of the LSTM model is as follows: input: encoded obscured word and the letters we have already guessed output: a 1 by 26 vector with each element between 0-1, indicating the probability of the next letters
- architecture: n is the length of word, time step is how many rounds we have guessed. The shape of X is 27 because other than 26 letters we need to preserve a space for "_".
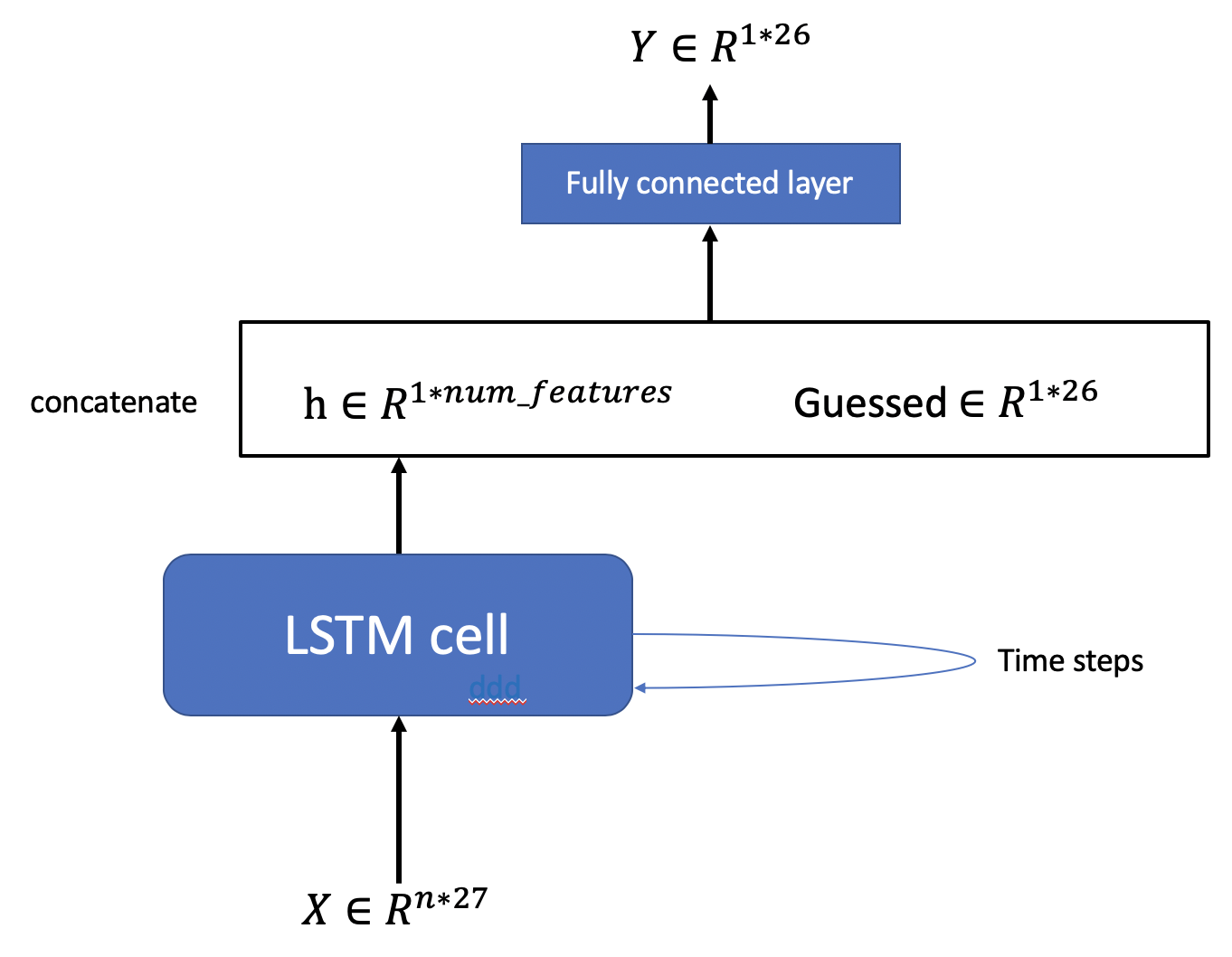
I trained the model using the simulated games generated from the training set (implemented in Word2Batch() class). I generated the training set following the next procedures:
- randomly select a word and make is all blank
- generate encoded label of this word
- let the model makes predictions in each step and generated the whole training set.
Training a neural network to play Hangman without a dictionary